并行化密集型计算
稍早前对 terser 压缩代码进行优化时将执行过程的代码从 Python 迁移到了 Node.js,准确地说是试图用 gulp stream 来批量压缩,用了一个比较老的包(gulp-terser),已经很久不维护了。与原先相比,底层都是 terser,只是为了在 Node.js 的镜像下使用而统一了文件的提取(glob)和批处理过程(Python Pool & subprocess -> gulp stream)。
但这样处理了以后发现压缩处理时长变长了很多,差不多慢了 1 分钟,研究了一下 gulp 的处理机制,发现虽然 gulp 号称流式处理,但文件依然是按个通过 pipe 的,前一个处理完下一个才能进入,但通过 parallel-transform 也能实现同时处理多个文件,可是实际操作中以 parallel-transform 替代 through2 并不能提升处理效率。笔者并未实际深究其原因,大致读了下 parallel-transform 的实现,它依然是围绕着 event-loop 做文章,设想成一个水池,干涸了就加水,满了就停止并等待处理完毕抬高基准线。
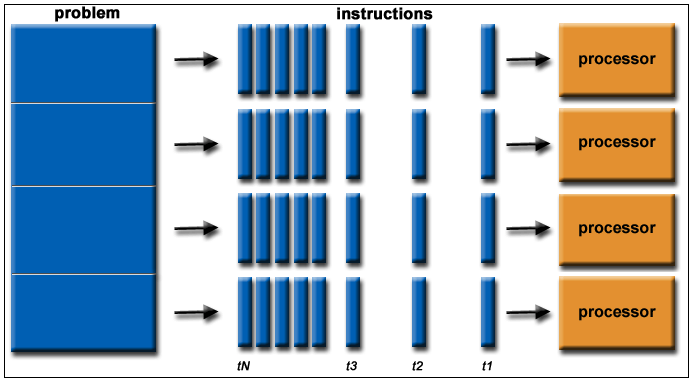
笔者甚至使用了 RxJS 来控制并发 …… 但事实证明还是自己太年轻了,这种密集型计算根本无法通过 event-loop 来优化,它和 ajax 或者 IO 操作不一样,处理数据的仍是这个进程,怎么办?那就多进程/多线程!
问题就变得简单了起来,第一步把文件列表拿到,第二步把它们分发到其他进程/线程处理。
首先想到的是 gulp.src 接受的是数组,而 glob 接收的是字符串,实现肯定不一样,事实证明果然相差甚远。想想看还是需要先拿到本着能不造轮子就不造轮子的思路,去网上搜搜代码,首先想到的是已废弃的 gulp-util。一看里面有个 buffer 符合我们的需要,直接抄来,只不过需要注意一下这里有个 cb 需要塞到 fn 的回调里去,这样才能准确得到 task 的总共执行时间。
1 | var end = function(cb) { |
fn 是个耗时的操作,必须再它完成后再 cb
然后按照 terser 和 child_process 的关键词找到了 @bazel/rules_nodejs - terser 这个包,简直是宝藏 …… 一顿大抄特抄,写死了 terser 执行参数,加了个 Promise 的返回值。上 pre 跑了一下,功德圆满!
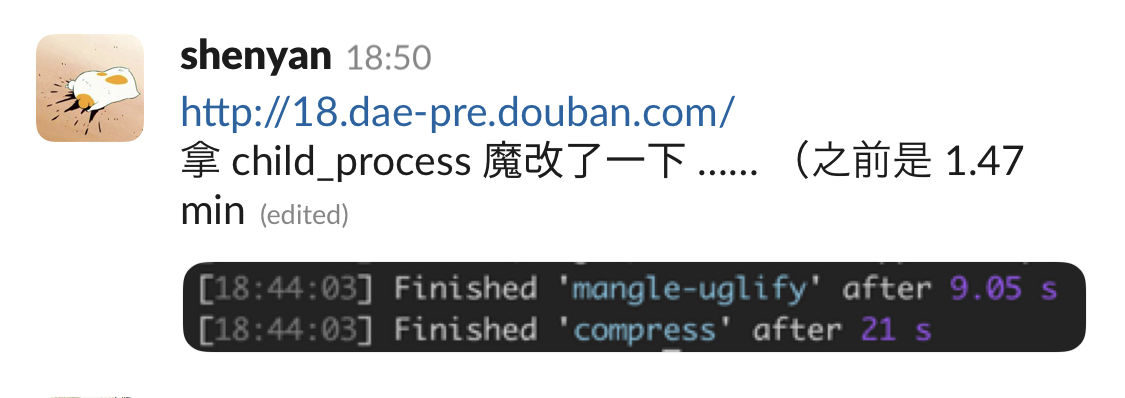
为啥这么快?看了下 CPU 数量,我惊呆了!
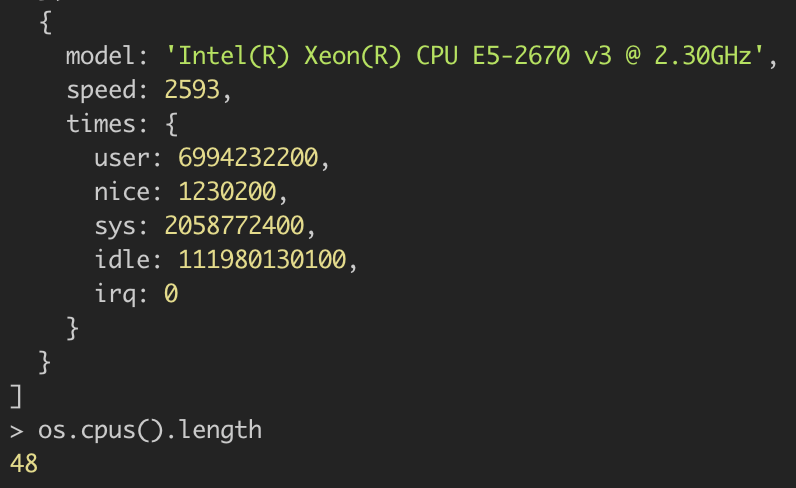
顺便看了下 issue 里也有试图引入 works_thread,不过 child_process 已经足够香了!
不过 web 上毕竟一个 page 只有一个进程,所以要有 Web Worker 来让密集计算在主线程之外运行,而可预计到的是 Web Worker 和 work_thread 的关系就好比 wasm 和 wasi,激动人心的进展!