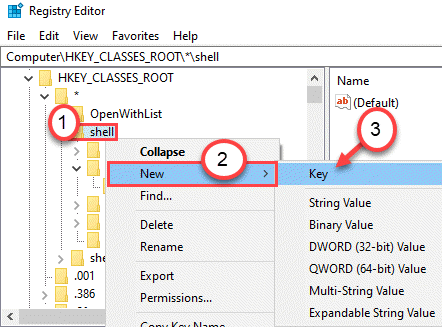
Electron 应用整洁架构
一个好的架构是具有良好用户体验的 App 的必备素质,反而言之,一个差劲体验的 App 一定是架构混乱甚至没有架构的。一坨一坨互相依赖,单例漫天飞的代码,足以让任何一个开发满嘴跑 F**K。
什么是好的架构?众说纷纭,但至少类似洋葱模型的中心化组织形式比较符合心智模型。设想一下,每天睁开眼睛,第一件映入脑海的事可能是下列这些问题:
- 我是谁?我是一个程序员,我每天需要写代码赚钱……
- 这是哪?这是我家,租来的房子,离公司骑车 15 分钟,所以我得赶紧起床了
- 看看今天有啥新鲜事?拿起手机,把通知和各个 IM 应用点一遍
- 开始新的一天吧?打开水龙头洗漱,出门扔垃圾,扫共享单车去上班
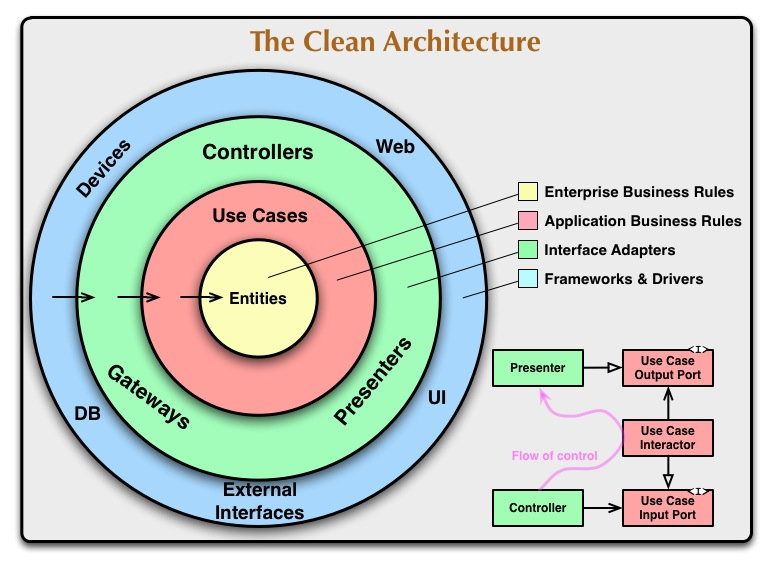
而这些想法和行为正好对应了 Clean Architecture 里的 Entities、Use Cases、Interface Adapters、Frameworks and Drivers。我是实体,我每天根据情景有要做的事,我接受的信息有原始的自然信息(如鸟鸣虫叫)也有经过加工的人工信息(明星八卦、国际局势),最后和社会的水电交通等公共设施打交道。任何一种好的架构都应该符合普通人的基本认知才能绵延不息。
光说不练假把式,同样以 Electron 框架为例子。为啥总要举它作为栗子呢?因为 Electron 天生具有 C/S 架构,同时又是客户端应用,可以说在单个体上参杂了前端、后端和客户端三种不同关注点的开发视角,所以大多数 Electron 应用往往都是一个大窗口套一个 web,主进程简单做了个数据层就完事。这种情况下既不需要架构,也不需要优化,只需要把代码堆积起来就完事了。
但时间一长,各种问题就粗来了:
- class 没有统一初始化的地方,基本是直接 export new 或者单例模式
- 功能堆砌纯线性组织,一条长长的 main 函数把所有的功能都包含了
- preload 脚本需要 ipcRenderer.sendSync 通讯,同时 ipc 可能遇到跨 frame 通讯问题
- 单元测试困难,Electron 模块随处可见,需要多次 mock
没办法,不想脱裤跑路就重构呗。天不生 Nest.js,Electron 架构万古如长夜!经过近两年的苦苦摸索,在尝试了至少三种框架的基础上,终于提炼出了用 Nest.js 框架良好组织 Electron 应用的方法,且听我缓缓道来。
框架特性
每个框架都会把自己的杀手锏特性都排在官网最前面,比如 React 是组件式,Vue 是渐进式,Angular 是让你有信心交付 web app,Svelte 是消失的框架(无运行时 lib),而 Nest.js 几乎是把渐进式、可靠性、扩展性等等都包圆了。实际使用下来,可以说是跟 Angular 一样的总包框架,可以管理一个 App 从启动到关闭整个生命周期。同时它也借鉴了 Angular 很多的创新点,比如依赖反转注入,装饰器模块,五花八门的中继器,以及强大的可扩展性,这也是我们得以将其应用到 Electron 项目的关键。
对于纯命令行程序,我们可以直接一个函数从头执行到尾再退出 App,而对于任何 GUI 程序,通常的解决方案都是以事件循环阻塞整个进程直至收到退出 SIGNAL,但这带来一个问题,如果进程被阻塞了,后续所有操作都无法得到响应。Node.js 的异步事件循环完美地解决了这个问题,在此基础上设计了基于消息的一系列运行机制,很好地处理了成千上万的请求。既然作为服务器都顶得住,那单机应用区区几个请求的并发更是不在话下。
我们设想这样一个应用:
- 它具有处理自定义请求事件的能力
- 它支持中继并更改请求,也就是中间件的能力
- 它可以分析模块依赖并自动按序加载
- 它可以加载外部网页并与之通讯,同时也可以与宿主机的其他应用通讯
这是一个跨端的带界面的服务器。
依赖反转
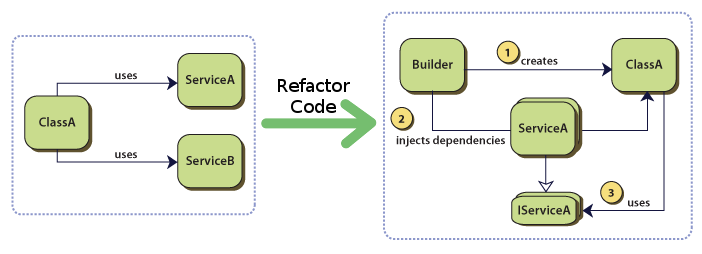
这个特性可太重要了,可以说没有它就没有后续所有的模块设计。每个上古项目都有一堆不明所以的头文件或者配置文件,或者不知从哪引入的构建脚本,又或是一串 token 或密码,这些东西都应该被管理起来。
我们需要一个简单的心智模型,所有第三方内容都是输入资源,不管是代码还是配置,webpack 就是把所有的内容都当作资源对待。但 webpack 在打包时也支持给 import 加参数,比如指定图片内嵌为 base64 的最大体积。支持输入参数也是我们的模块建设目标之一。
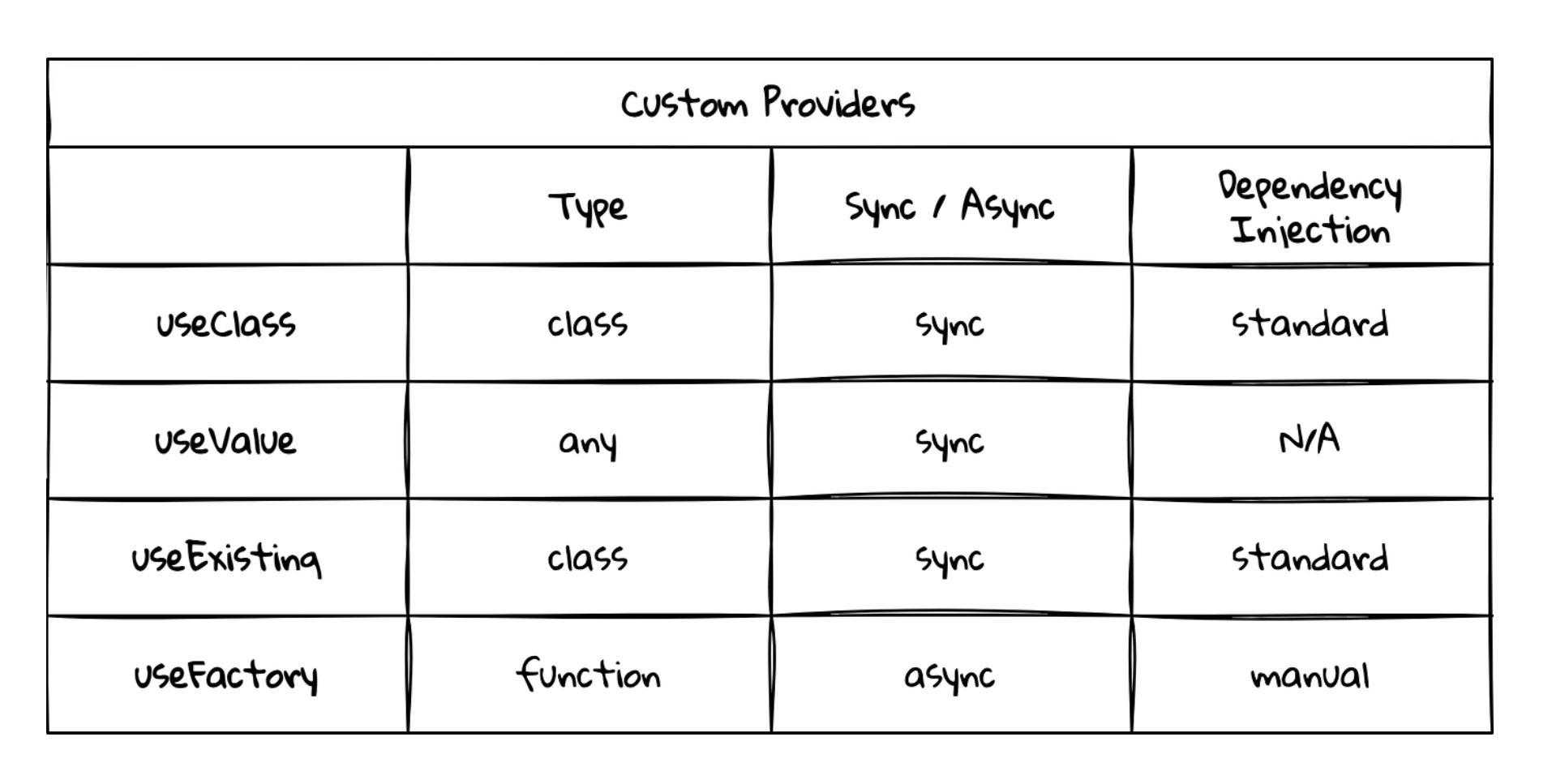
同时,webpack 也支持拆分模块,延迟至使用时加载,这一点更是杀手锏。因为客户端的生命周期一般比网页要长得多,但对体积相对不敏感,使用一些 preload 技术可以不在影响用户正常使用的情况下在快速响应页面和保证功能随时可用间达到平衡。使用 Nest.js 的 useFactory 可以轻松将模块变为 import(...) 延迟加载并且在使用时只需从 constructor 进行注入,避免全局的 lazy import 污染。
模块存在的意义就是复用,虽然 web 上各种框架的教条都是不要复用组件,多用组合而不是嵌套继承,但实际上数据和 UI 就是不同的组织形式。我们可以精确定义每个模块的使用究竟是全局唯一,每次实例化使用一个新的,还是每次调用就直接新建一个。
参考:
路由模式
组件是前端的组织方式,而路由则是后端的组织方式。
路由模式和消息监听机制很像,区别是路由是编译时即唯一确定的,而消息监听则往往是运行时动态注册。这里动态注册的消息机制带来了两个严重的问题:
- 首次加载时无法确定消息处理的顺序,往往需要等待一个消息监听器绑定之后再触发事件,要是没监听上就丢失了。
- 消息监听可以放在全局,或者跟随模块。前者污染了全局环境,后者层层嵌套之后难以确认依赖层级。
既然消息机制具有如此多的不稳定性,我们还是更倾向于跟服务器一样一次性注册所有路由。
不管是 HTTP 还是 IPC,甚至系统菜单,都可以作为路由端点。我们也可以用自带的 EventEmitter 在应用间不同路由间穿梭。下面这段代码就演示了一个简单的创建或更新对象的路由端点,可以看到路由的组件由装饰器标识,在函数参数里通过装饰器来捕获不同的参数,经过 this 上的数据库及 logger 对象,完成了数据的持久化和日志功能,最后把创建结果以 JSON 格式返回。
1 | ('/:id') |
装饰器-decorator
大家肯定也看到上面代码中四个大大的 @,这就是 JavaScript 中的装饰器语法。只是可惜的是 parameter decorator 最终没有进入 stage 3,也就意味着 Typescript 以后肯定会对这个调用方式进行更改,不过这件事还没有尘埃落定,加上这么大一个框架,根本不用担心。
让我们庖丁解牛一下“装饰器”究竟是个什么东西?装饰器的重点自然是在装饰上,也就是给被装饰的类、函数方法、参数等实现一个不同的外观,从而在程序运行起来时以指定的方式调用/生成被装饰的对象。这句话读起来还是很别扭,实际上装饰器是元编程的一种形式,也就是不改变代码结构的前提下给代码走不同路径的方式,可以理解成打补丁。
举几个例子,比如常见的 debounce 和 throttle 方法,它们接受一个函数,返回防抖和节流后的函数版本。
1 |
|
无装饰器版本
1 |
|
装饰器版本
可以看到装饰器版本将业务逻辑内聚成了一个函数,而不是必须要用函数套函数的方式。让代码分层有助于隔离关注部分,我们通常会把路由的执行逻辑和路由的路径给绑定在一起,但又不想变成每个路由端点都是一个类,这就是装饰器常见的应用场景了。
HTTP类
Nest.js 自带了很多 HTTP 服务的默认装饰器,对于绝大多数场景而言已经足够了。支持 HTTP 不同的请求类型,从请求中获取数据,并最终将内容用模版拼合并返回。
- 路由:@Get / @Post / @Sse
- 参数:@Param / @Header
- 响应:@Render
自定义类
- 获取参数:@WebContents
- 装饰路由:@IpcHandle, @IpcOn
除了 HTTP,Electron 应用还内置了一种消息通讯机制,就是客户端熟知的 IPC(Interprocess Communications)。它的实现可以有很多方式,不同平台也会有不同的实现,但 Electron 的特殊点在于 IPC 两端绑定的不是进程或者 socket 连接,而是 web 页面。
Web 页面承载了实际展示给用户的 UI 内容,它本身存在于一个个渲染进程里,主进程里可以认为只是它的一个替身,但实际运用中往往需要拿到这个替身的各种状态。
既然是统一了 HTTP 和 IPC 通讯方式的框架,我们将会用装饰器抹平两者的差别,开发时可以自由选择通讯方式的同时也能支持拿到相应的请求源对象。
| 通讯方式 | 优点 | 劣势 |
|---|---|---|
| HTTP | 无需向 web 注入代码 | 无法自然获得 web 页面句柄 |
| IPC | 传输 JSON 无需序列化 | 需要向 web 注入对象 |
这里面会分别用到 Nest.js 的 Custom Transport,以及 Electron 的 WebRequest 模块。
- Step 1: 通过 @nestjs/microservices 的 EventPattern, MessagePattern 组合出 IpcInvoke 和 IpcEvent 装饰器(给路由用)
- Step 2: 通过
session.protocol.registerSchemesAsPrivileged放通自定义 SCHEME - Step 3: 在 WebRequest 拦截自定义 SCHEME(HTTP)请求头注入 webContentsId
- Step 4: 在 CustomTransportStrategy 绑定所有 Step.1 装饰过的路由响应 IPC listener,并在 handler 中传入 event 对象作为 data
- Step 5: 创建 WebContents 装饰器。通过 @nestjs/common 的 createParamDecorator,根据
ctx.getType == 'http' || 'rpc'来返回位于req.headers和RpcArgumentsHost.getData中的webContents
1 | /* 路由装饰器 */ |
1 | /* 参数装饰器 */ |
使用装饰器可以让我们更轻松地将不同的路由与 Electron 框架进行交互,不管是注册事件监听模拟路由还是从请求中解出需要的源数据,都很方便。
中间件-middleware
如果说装饰器是完成了路由的网状组织最后一块拼图的话,那中间件就是为数据的流动接上了一长条管道。
Nest.js 中的中间件有三种,Middleware,Interceptor 和 Exception filters,甚至 Pipes 和 Guards 也可以算作中间件。它们本质都是对请求和响应作一定的处理,来满足包括鉴权,错误处理,数据转换等等功能。
这是 Stackoverflow 上对不同中间件的总结。
https://stackoverflow.com/questions/54863655/whats-the-difference-between-interceptor-vs-middleware-vs-filter-in-nest-js
这张图很好地展示出了不同中间件在一个请求的生命周期中的作用。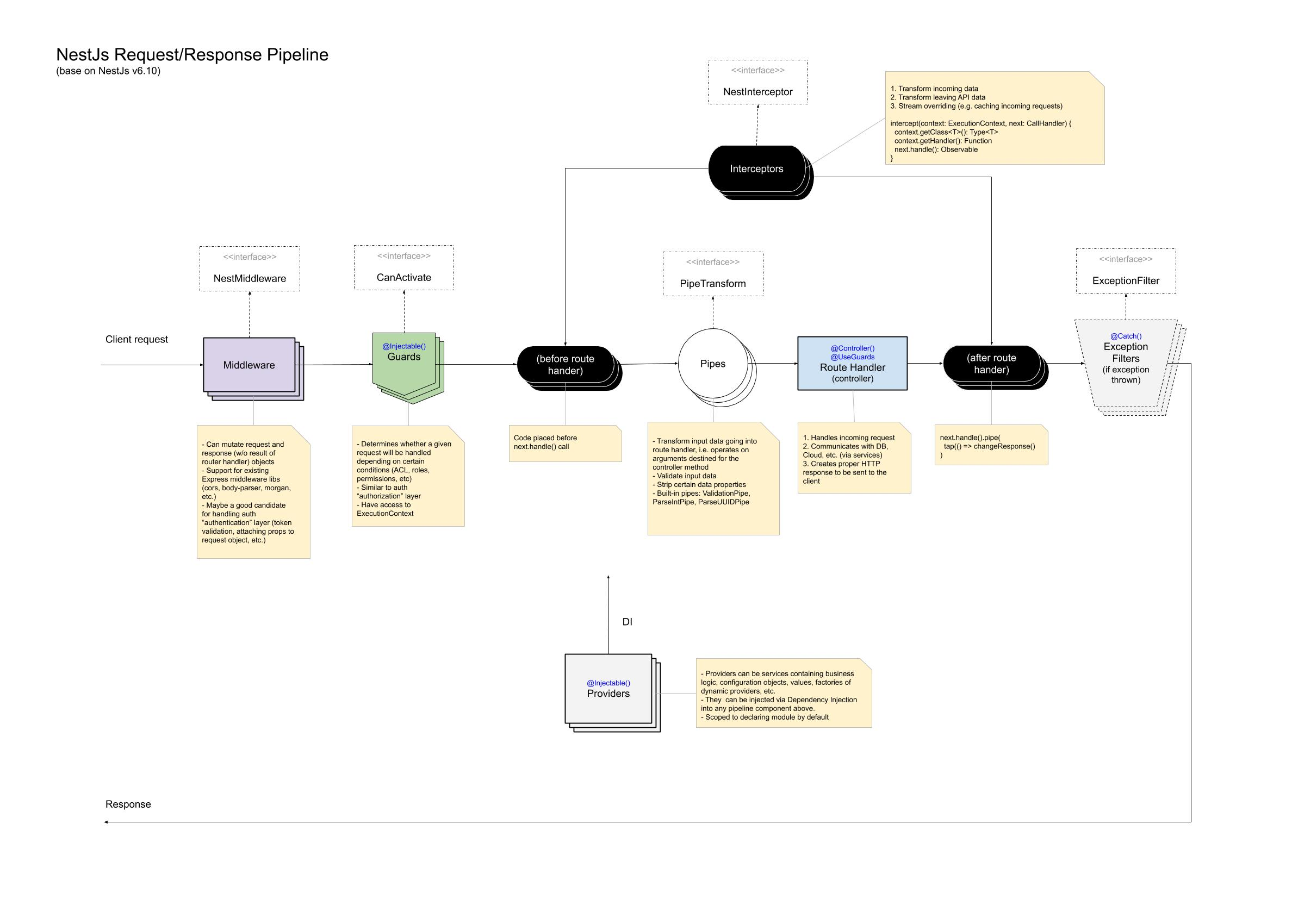
简单实现一个针对特殊路由对 JSON 路由返回结果,将 data 包了一层再返回的中间件。
1 | import { Observable, tap } from 'rxjs'; |
Web 后端服务直接将端口暴露在网络上往往需要很多的安全校验以及错误处理,实际上客户端代码是自主维护的,风险相对可控,所以不会需要太多的校验工作,只是对一些涉及到 C++ 调用时,因为数据类型需要转换,比如只接受整数,传入浮点数会导致类型转换失败甚至程序崩溃。中间件一些应用场景如下:
- 给 request、context 统一加上指定参数,例如 request.user
- 在请求处理完毕返回前继续调用别的路由端点
传输器-transporter
可能聪明的读者已经发现,前面讲路由的篇幅大部分都在介绍如何处理请求,但形如 app://create 的 URL 以及 IPC 监听器是如何被注册到应用之上的呢?下面就介绍一下两种注册方式。
自定义scheme
假设要处理 app:// 这样的一个协议,我们需要将这个请求转发到真正的 HTTP Server 上。通常情况下需要绑定本机的一个 TCP 端口,但这里有个问题,如果尝试绑定的端口被占用怎么办?可以用不断尝试的方式最终拿到一个可用端口,但更好的方式是使用 Unix socket。
1 | import os from 'os'; |
之后我们只需要将 Nest.js 的 listen 方法指向 getSocketPath 创建出的 socket 地址即可收发协议消息了。
ipc注册
注册 Electron 自有的 IPC 消息则略微麻烦一点,但好在 Nest.js 提供了 MicroServices 模块,允许我们自定义消息传输器。
因为我们在前面使用 EventPattern, MessagePattern 绑定了 handler,这样就能在 server 的 messageHandlers 里找到对应的请求处理函数,将它与 ipcMain 对接起来。示例实现如下:
1 | import { ipcMain } from 'electron'; |
最后在入口处加上这个 strategy 并随 App 启动即可。
1 | // microservices |
数据管理
前面我们讲到了如何处理用户操作(也就是各种各样的请求),这里谈下如何将请求的结果持久化,也就是记录数据。不管是前端还是后端,都有一整套数据 CRUD 的工具可以用,但到了客户端这边需要考虑的东西就变得复杂了起来。
首先数据库最简单的需要支持读写,是否支持多人同时读写?抛开写入而言,读取性能是否满足?如果数据库意外崩溃,是否支持根据日志回放等等。然后考虑到跨平台场景,还需要数据库支持不同操作系统不同架构等。根据上述问题分别分析不同数据库使用场景,各自的优劣势分析如下表。
| 存储方式 | 瓶颈 | 优势 |
|---|---|---|
| localStorage/IndexedDB | 仅限 web 使用 | 原生 |
| MySQL/PostgreSQL | 跨平台支持不足,且需要占用端口 | 生态丰富 |
| JSON 文件 | 可能存在读写竞争 | 单文件 |
| LevelDB | 文件数量多 | 跨平台支持,不限定文档结构 |
| SQLite | 需要固定单条记录结构 | 跨平台支持 |
最终,我们发现可以将简单的 KV 存储和复杂结构数据区分开来考虑。
简单JSON内容与跨进程
JSON 存储主要突出一个字:快。这里通常的数据量级都不会超过 1kb,无论是 set 或是 get 都可认为是同步完成的,会带来以下好处:
- 无需 async/await 写法,跟普通 JavaScript 对象一样操作
- 单文件 debug 方便,任意编辑器直接查看
- 同上一条,单文件可直接跨进程访问,web 与 Node.js 之间可通过 JSON 共享数据
下面将实现一个从主进程写入 JSON 数据,preload 中读取数据的 demo。
1 | // main-process |
1 | // preload.js |
数据库的初始化和关闭
客户端所用数据库跟普通后端数据库没有太大差别,只是得注意需要有不同系统及架构的二进制包,事实上例如 SQLite 和 LevelDB 都有官方的 node binding 版本,只需要打包时一并合入发布制品即可正常使用。但如果是在 Electron 项目中,则又多了一项准备工作,那就是如何获得数据库的存放位置。
其实任何存储都有类似的问题,前面的 electron-store 也不例外,需要在 new 的时候知晓确切的存储位置,但这是一个异步过程,简单表述如下。
1 | import { app } from 'electron' |
为啥要 await app.whenReady() 呢,因为可能会有让用户指定目录或者运行自动化测试需要传入特定目录的需求,比如 Chrome 就提供了 Overriding the User Data Directory 的选项。
但这里带来一个严重的问题,所有使用数据库方法的地方,都需要加上 await 来等待 Electron 的 ready,这样看起来很不科学。有一种办法是给所有的方法都加上一个装饰器,sync 方法也变成 async 方法,但这肯定不是我们想要的。怎么办呢?我们需要用前面提到的 useFactory 来包装一下这个 ready 事件。
1 | // module |
1 | // database |
我们看到上面的代码中,userDataDir 变成了一个 Injectable Provider,可以被随时注入到例如数据库 constructor 里,这样不仅避免了 async 写法,还能让 Nest.js 自己管理依赖关系。
理想情形下,退出 App 前还需要关闭数据库操作,这也可以绑定到 Nest.js 的退出回调监听器上。
数据目录分类
前面提到的数据存储操作,最终都需要将数据写入磁盘目录,而且我们也看到了这里面使用了 userData 这样的目录。实际上 Electron 给我们封装了各种系统预置的目录,让我们来了解一下它们分别是什么用途,以便更好地设置。
| 名称 | 说明 |
|---|---|
| appData | 程序目录,不要动这里面的文件 |
| userData | 用户数据,大多数数据都应该放在这里 |
| temp | 临时文件,一次性数据,关机后不保证可以留存 |
| downloads | 下载目录 |
| logs | 日志目录 |
这里面没有提到一个很关键的目录,就是 cache 缓存目录。默认实现时,缓存目录和用户数据在同一个路径下,但我们往往希望它能位于一个隔离的路径下,以便用户觉得占用过多空间是主动清理。可以通过以下方式拿到这个 cache 目录。
1 | import os from 'os' |
简单总结一下,Electron App 的数据存储与普通 Node.js 应用类似,都是通过一定的映射方式,或以文件或以记录的方式存储到磁盘上,只是需要考虑跨进程读写及数据的初始化配置问题。
会话隔离
绝大多数人都会在 web 上使用各式各样的账号,这里就出现了一个问题,如何在同一个网站登录不同的账号呢?有的人做法是开一个隐身模式窗口,dddd …… 但实际上浏览器本身自带多账号功能,称作 session。前文里提到的不同 --user-data-dir 可以让 Chrome 多开成为现实,不同用户间的数据是完全隔离的,但这需要启动多个进程。合理利用 chromium 的 session 可以在同一个进程内实现登录同一个网站使用不同 session 的功能。
使用不同 Session 不仅可以隔离账号,还可以针对不同 Session 定制特殊行为,比如支持自定义协议,对 web 资源进行缓存等,妥妥就是一个 web 定制沙箱。
Session持久化
使用 Session 第一步,要将 session 数据持久化。有人会说 sessionStorage 不是在浏览器关闭 tab 后会被清除吗?事实上此 session storage 非彼 sessionStorage,这里的 session 指的是包括 cookie、localStorage、IndexedDB 以及 sessionStorage 在内的所有 web 缓存。如果没有设置成持久化,那 Session 就变成了隐身访问模式。
设置 Session 持久化只需要一步,就是创建 Session 时传入前缀为 persists: 的 partition。在 Electron 代码中即有这个常量,这也是为数不多通过字面量判断表达不同目的的 API 之一。
不同的 Session 会出现在 Partitions 目录下,persists: 后面的文字就是目录名,里面密密麻麻都是 Chromium 运行时产生的数据文件。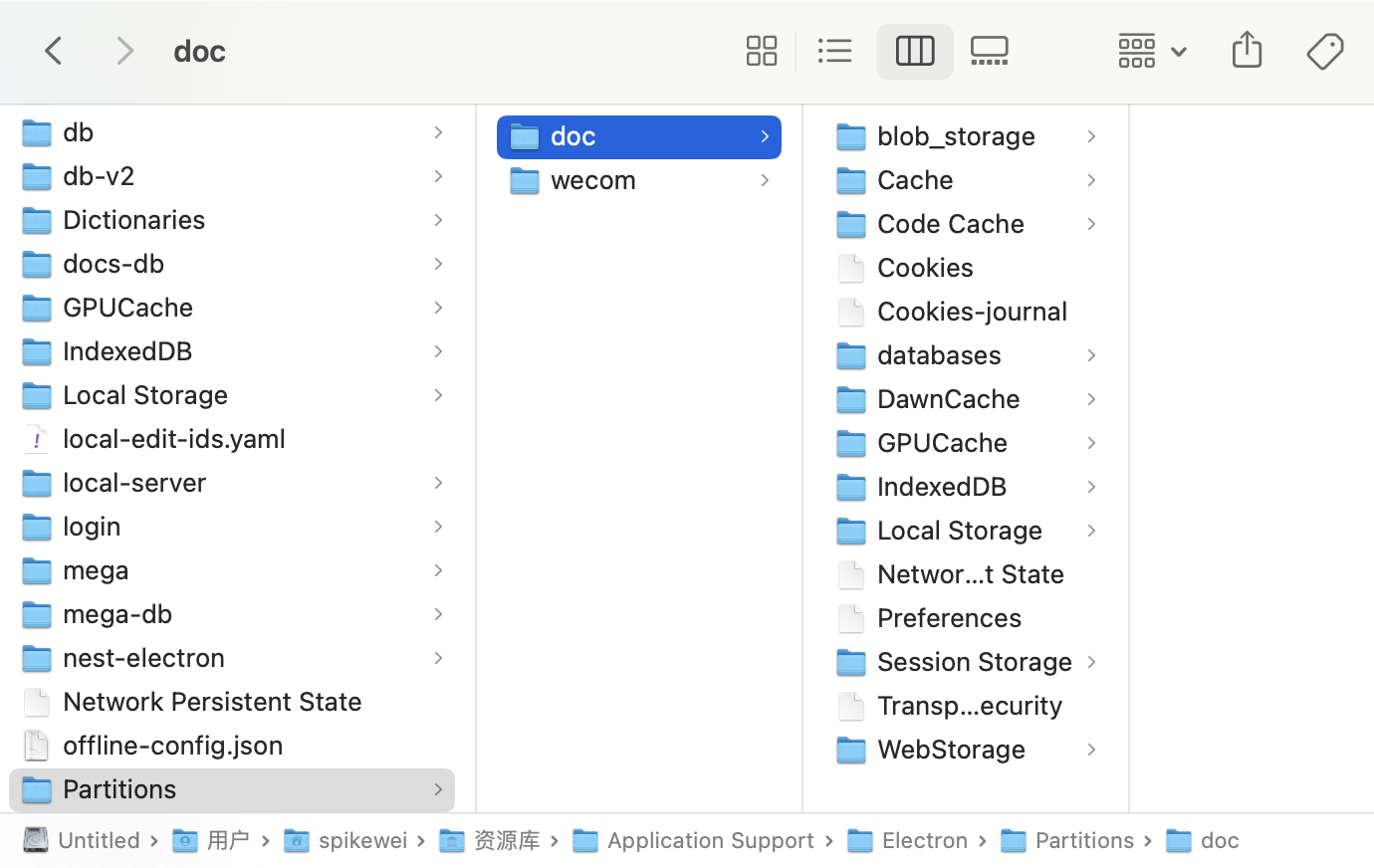
Session事件
与 IPC 消息可以只在全局 ipcMain 对象上监听不同,不同的自定义协议、网络请求和 cookies 都只能从单个 Session 上获取,这是一把双刃剑。一方面我们需要在不同 Session 初始化时绑定事件监听,甚至在 app 启动时注册协议,另一方面同样也能对 Session 进行隔离,以防某个 Session 崩溃影响到别的,这也符合 Chrome 对于多渲染进程安全和效率之间的平衡。
简单来讲,Session 上有 protocol、webRequests 和 Cookies 这些对象可供调用,分别提供了协议拦截、请求拦截和 cookies 操作的功能,注意这不是 Chromium 的全部功能,所以可以预见的是这个树状结构会越来越长。
以上三个对象的操作方式大相径庭,下面为简单分析:
protocol 比较纯粹,对某个 scheme 比如
app相关的请求拦截并响应,可以理解成后端服务器的 server。
webRequests 需要设定 url pattern 匹配规则,对规则内的请求做处理,或改变 header,或进行重定向。但这里可以拿到请求的 webContents 对象,所以可以做一些特殊的操作。不利之处是,url pattern 及 callback 在单个 session 同一 hook上只能注册一次,所以遇到多 pattern 匹配需要自己手动做拼接及分发。
cookies 同样很纯粹,它就是 web 内 cookie 对象的真身,只是移除了跨域读写 cookie 的限制。
Session 可以说是 Electron 的命脉,虽然大部分情况下都不会跟它打交道,但它往往是一个 Electron 程序运行性能的瓶颈。
业务特性
铺垫了如此长的篇幅,Electron App 都快走到了它生命周期的尾声,这才来到了我们开发它的初衷:完成指定的功能。
一个理想的 Electron App 就应该像 VSCode 一样,本身提供渲染排版编辑的功能,其他功能以插件形式补充。事实上类似 TypeScript 支持这种也是插件形式提供,虽然它们在 VSCode 使用过程中就像呼吸一样自然。Electron 本身是一个容器,它承担了大部分 Clean Architecture 里内三层的工作,将系统和窗口的功能封装成 API 提供,只不过这些 API 对于实际应用来说仍然太底层了,还需要一个 Adapter 层来整合梳理。这就是插件机制所要做的事了。
但作为一个 GUI 应用,完成用户功能必须要跟窗口紧密结合起来,少不了要和各种创建修改窗口对象的 API 打交道,但实际看来这部分工作量反而是比较小的。
插件机制
上图是一个简单的剪贴板与窗口联动的功能分层,插件的 API 设计位于倒数第二层。在设计插件时有时会进入这样一种误区,插件的功能直接调用了系统功能,从而跟系统的版本有了耦合,这就是即当业务开发又当技术架构的弊端,因为自己写着方便就耦合在一起,最后导致项目架构越来越混乱。而插件机制正是起到了“防止业务特性侵入架构内部的防腐层”作用。
内置插件
虽说几乎可以通过所有的 API 将功能都暴露给不同的插件,但事实上有些关键插件是无法直接提供给用户进行设置的,一来是可能用到了内部不稳定 API 不准备让第三方进行操作,二来是影响范围很大,比如主题色和 UI 展示位置等,毕竟用户也不希望一旦安装了某个主题就把自己熟悉的工具栏位置给换了。这就很像政治课本上讲的,国有经济对国内市场的控制在于控制支柱行业。
VSCode 常见的内置插件范围为:
- 主题色设置
- Git 功能
- 账号功能
- 搜索
- 内置浏览器
- 语言 Debugger
- 语言语法检查与高亮
可以看到这些功能都属于深入到了应用程序内部,一旦缺失都无法正常运行了,所以必须是全局启用的状态。
第三方插件
没有什么插件是调用一两个 API 解决不了的,有的话就出一吨 API 接口!
VSCode 提供了汗牛充栋的 API 列表,同时还有对每个 API 详尽的注释说明,可以说文档能力才是一个公司技术实力的真正体现。
https://code.visualstudio.com/api/references/vscode-api
但除了插件调用 API 完成功能之外,还有一些配置信息,这就是 manifest 文件做的事了。比如配置了 onLanguage 字段后,当识别到一个文件为特定语言时就会给插件发送消息。

https://code.visualstudio.com/api/references/extension-manifest
插件依赖
插件一多,就跟模块一样存在互相依赖的问题。内置插件还好说,毕竟在同一个仓库里维护,第三方插件完全是脱离控制的存在。
一种简单的办法,插件具有版本,互相引用需要带版本号进行关联,但很明显这是种不经济的做法。况且为了不强依赖于某个版本,大家都会心照不宣地做成向上兼容模式,这时候一个实习生发了 x.x.n+1 的版本,但实际废除了一个重要 API,画面太美不敢想象。事实上没有一颗避免循环版本依赖的银弹,业界通常做法是深度遍历之后在遍历到一定层数,返回循环依赖的报错。
这时候就不得不提一种脱离 RestFul 的查询语言:GraphQL。用它进行查询时,所有的层级都必须显式注明,无法进行无限嵌套查询。这有点像加上了 SQL 的 RestFul 接口,并且它还支持动态 join。
我们可以设计一种生命周期,插件安装完成后根据一系列钩子获取到插件系统的状态,同时将输入输出连接到插件系统,这样任何的行为表现都交给了系统。比如插件 A 需要插件 B 的数据,它会试图先询问系统在存储空间内有没有插件 B 写入的数据,得知不存在时请求调用插件 B 的功能,得知插件 B 不存在时唤起插件系统的下载功能对插件 B 进行加载。
窗口 UI
Electron 对于 UI 的表现力主要来自于 Chromium,也就是 web。做 UI 没啥复杂的,就是改改改到地老天荒就完事了。UI 一定不能直接暴露给插件或者第三方,因为要描述 “使用确认弹窗提示用户后续操作有风险”,要比描述 “创建一个长为 xxx 宽为 xxx,坐标为 (xxx, yyy) 的窗口,并在其中放置标题为 xxx,确定按钮,取消按钮,点击确定按钮继续,点击取消则放弃” 要方便得多。
UI 本身即是很难被准确描述和展现的,对于外部插件而言,只需要关注改变 UI 的方式,而不应关心 UI 元素的组合和操作。
KISS
不要动原生对象!
不要动原生对象!
不要动原生对象!
重要的事说三遍。因为 Electron 中几乎每个对象背后都绑定了 C++ 的对象,只是 C++ 在前台的一个傀儡,所以 class 的 constructor 并不能正常的在子类里复写。有啥需求请老老实实拿到 Electron 提供的对象再操作,最好是 Electron 端的 API 都进行包装,并通过依赖注入使用。
抽离重复判断逻辑
React 一声炮响,为前端带来了声明式 UI。但基于 Virtual DOM 的渲染机制最近越来越式微,究其原因不过是 UI 组件的膨胀非常剧烈,层级也越来越深,跟 OOP 中类的继承一样是个无底洞,不管是常规 diff 还是分优先级 Fiber 机制都无法满足正常渲染出数据对应的页面的要求。更精细的应该是接管所有数据源头,根据源数据的变动来处理最终更新。但现在大部分前端页面还没有复杂到这个程度,处在刀耕火种还是飞机大炮的中间地带,React 就像是蒸汽机车一样提供了强劲的 UI 驱动。
回到我们的应用来,Electron 给窗口(BrowserWindow)提供了很多操作方法,但这里有个问题:如果要检测窗口是否可以做某个操作需要有一些前置判断逻辑,这些前置步骤很难封装。如果我们使用的是路由模式的话,理想情况修改窗口 UI 应该是下面的模式:
1 | class WindowController { |
其中 @Prevent(['maximized', 'hidden']) 标识这个操作只有在 window 不是最大化或是隐藏的时候才会被调用。基于 Nest.js 的中间件还可以将更多 API 安全地暴露给外界,我们的应用不再是一个闭门造车的状态。
中心化状态
最好的状态管理就是不作状态管理,像页面 URL,Electron 全局对象等都可以充当状态管理器。但这里要注意一点,如果渲染进程和主进程都要用到一种状态,那合理的模式应该是:
也就是所有的状态都由 main-process 持有,renderer 通过订阅和传送消息来和应用交互。前面讲的所有消息都是从单次往(返),该如何实现订阅机制呢?在 Nest.js 下也非常简单,使用 Server Send Events 即可。
https://docs.nestjs.com/techniques/server-sent-events
最佳实践
软件开发没有银弹。只是在遇到 DDL 临近,PRD 只有两句话,屎山代码一片又一片时,是否还能保持内心的镇定,找出相对更优的那个解,这应该是每个工程师都应该思考的问题。
防呆设计
虽然只是一个很小的点,但实际操作中还是很容易被忽略,那就是没有一个用户会 100% 按照你的预期来使用你的产品。例如给用户一个删除按钮时,用户会毫不犹豫地点下它,然后等待确认删除的弹窗弹出来。什么?直接把文件删除了?你们这是欺诈消费者。所以业界共识都是删除往往都是只标记数据为已删除而不是真正删除,实际在磁盘清理或是存储服务缩容时才会丢弃这部分数据。但不符合用户预期的行为一定会带来用户的困惑,所以一定需要反复确认这种反人性但必要的功能。
另一个小点,用户的数据是我们第一优先级要保障的内容。撇开上面用户主动要删除资源的情形,如果遇到不可抗力,比如网络错误,或者数据格式解析失败,第一步也是尽可能备份用户的数据并提示用户自行转移,而不是失败了提示刷新页面,用户一点,咣的一声数据就没了。这就是为什么危险操作往往用红色标识,但一种趋势是:用户甚至不关心你在表达啥,他只是想把这个该死的弹窗给 × 掉。所以 Windows 更新才会以那么粗暴且不可取消的方式抢占用户的操作。
保持功能独立
没有什么比功能耦合更折磨程序员了,简单的小功能往往最后变得不可收拾,这通常是产品 feature 没有被良好地拆解消化,也可能是 DDL 倒排导致的赶工。总之,连 Chrome 都只能用多进程来解决不同网页的内存泄漏问题,就更不用说我们这些仓促写就的代码了。保持功能独立主要有以下几点:
- 数据的唯一性,参数的正交性。这个可以参见我之前的一篇文章掌控前端数据流,响应式编程让你看得更远,只有做到数据独立,才能最大程度减少错误状态给整体带来的危害。
- 对于外部 API/SDK 足够的不信任。也就是说任何未经严格测试的第三方内容都需要加兜底处理,以防击穿层层防护使应用崩溃。
- 组合优于继承。虽然这是句老生常谈的话,但实际运用中,加一个 if else 或是添加一个类似命名的方法都是在进行继承操作。如果有那么一点成本上的可能,我们甚至应该对每时每刻每分每秒的代码都部署一个版本,这样我们总能在漫漫时间长河里找到能用的那个版本。