如何从前端到客户端
我是如何从一个工作全部内容只是 HTML + CSS + JavaScript 的前端,转为一个依然基本靠着前端三板斧技能工作,但支撑起了”横跨三大操作系统 + 各种处理器架构 + 保持 web 同步迭代周期 + 复用了 web 95% 以上功能的桌面端产品“的伪客户端工程师?
首先当仁不让地要祭出 Electron 这件大杀器,现在开发一个桌面端最最行之有效的方式仍然是 web 套壳,让 web 代码几乎不用改就可以直接运行在一个窗口里。如果采用别的技术方案,我曾不止一次地在前同事和当下 leader 等口中听到拿 C++/OC/Swift 之类的写界面要吐血三升之类的话语,理解各种 Window、Dialog、Layout、Signal & Slot 就足够一个前端喝一壶了,而这些技术细节在 Electron 下都可以化繁为简成一个个普通的 Chrome 窗口,以及与之相关联的 Node.js 胶水逻辑。
Electron 更接近于 Hybrid 应用
虽然把页面展示出来只是客户端面临的众多问题之一,但这恰好是客户端做 UI 最复杂的那一部分。
使用 Electron 就是说我可以在不改变主要工作语言的前提下,尽可能快且大地延展自己的作业范围,以较低成本快速搭建起原型,这是前端选择其他语言或者框架进行客户端开发无法企及的优势。
那是不是只要上了 Electron,把 web 页面一封装就万事大吉了呢?倒也不是,客户端开发上接网络通讯、界面渲染,下至系统特性 API,它这个逻辑不是后端来一个 request 返回一个 response(简化模型),也不是前端从一个页面加载到脚本执行后进入等待 UI 交互的过程就结束了。客户端需要同时处理多个页面的展示、管理前后台进程、与服务器做通讯、主动存取数据至文件等。
| 角色 | 替身 |
|---|---|
| 后端 | 收银员/会计 |
| 前端 | 导购/客服 |
| 客户端 | 客户经理/维修人员 |
我更偏向从角色和现实生活中的替身角度认识各个端的分工,这个分工不是绝对的,彼此之间有交集。前端主要负责 UI 的展现,像是一个商店的导购小姐,根据用户喜欢安排不同的商品;客户端则是客户经理,向已经对此感兴趣的用户进一步演示商品的功能,并分析深层次用户需求;后端则是收银员兼会计,这时候用户已经拍板下单了,如何收钱,如何签订协议,如何发货和三保。之后可能还会有进一步交互,比如用户发现商品出了问题,继续通过网页上反馈过来,然后客户端需要更新版本,相当于以旧换新,完成持续交付。
下面我将从四个角度来阐述我对客户端开发的理解:
技术应用
抛开具体使用的语言或者框架,不同的职位或者开发方向在解决用户需求和技术问题上有着不同的纵深,意味着“术业有专攻”。这一点很多时候属于给用户一把锤子,他就看啥都像钉子一样,由不得你,甚至还会倒逼你去一步步提升体验。
剪贴板
既然都上了客户端,想必用户需要频繁操作的了,这就免不了要和键盘及鼠标事件打交道。常见的输入方式还好,就跟浏览器基本一致,只是遇到过 Mac 上无法通过快捷键复制粘贴的问题。说来都离谱,作为一个文本编辑软件,发布出去时竟然无法使用快捷键 Ctrl + C + Ctrl +V!还好我们很快就发布了版本修复了这个问题。
而后我们又发现了右键菜单也得自己实现,不由感叹浏览器真是个复杂且贴心的玩意,给前端实现了如此多的功能。右键菜单部分同样是由 Electron 封装好了大量具体系统的 API,只需 JS 调用即可。
这些可能还是看得见的部分,看不见的部分,比如系统的剪贴板?如果我们想要模仿手机上长按复制文本至 App 内识别链接并打开对应页面的功能该如何操作呢?
因为各系统的剪贴板实现都是不同的,Web 上早期使用 execCommand 来与剪贴板交互,现在则有 Clipboard API。看起来很美好,只是致命的是 clipboardchange 事件尚未被 Chrome 实现 …… 这里陷入了前端的盲区。
Async Clipboard API - clipboardchange event not fired
从前端角度走不通,可以看一看 Electron。Electron 本身自带了一个 Clipboard API,上面有各种读取文本、富文本数据、图像的方法。同时,发起检查剪贴板的请求倒是容易,再不济也可以用轮询。做得细一点可以用 RxJS 来订阅一个根据鼠标聚焦窗口事件 + 剪贴板文字 + 去重 + 抢占式的调度模型:
这里有个问题:当用户重复复制同一段文本进入到我们的客户端时如何判断出来呢?文本比较肯定是失效了,系统层面前面也了解过没有一致的剪贴板改变事件,所以只剩一条路,就是标记这段文本。
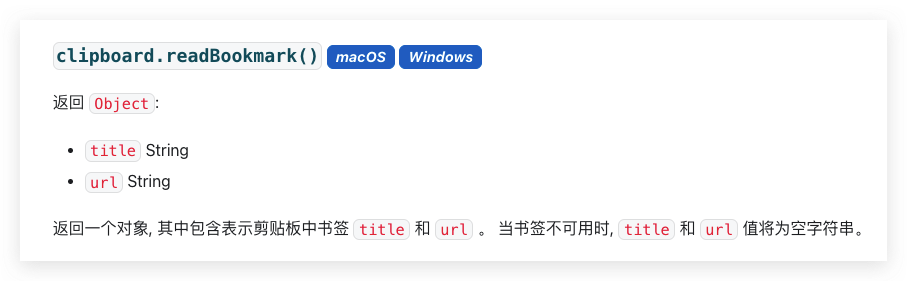
因为绝大部分程序只读 bookmark 里的 url 而不会去读 title,可以用 title 来标记这段文本已经被我们的客户端识别过了,当用户再次从任意地方复制了文本时会清除掉这个 bookmark,也就达到了我们标识已经过 App 识别链接的文本的目的了。
到这里我们发现,客户端的开发与前端正在趋同,两者都会深入系统提供的功能,又期望第三方库或者浏览器能提供标准的接口。
安装与更新
作为前端开发,页面关闭或刷新时,整个页面所有的元素都被销毁了,重新载入就是一张全新的白纸。而客户端不一样,下载下来就在硬盘占据了几百 MB 的空间,那可是战战兢兢,指不定哪一天用户嫌体积大就给卸载了。怎么办?当然是与时俱进,网页的优势在于刷新就是新版本,而客户端就只能老老实实做一键安装与自动更新了。
本着用户价值最大化的原则,现在软件大多抛弃了争奇斗艳的安装界面,反正做得越花哨越像流氓软件,Electron 社区标配 electron-builder 打包时提供的默认安装功能就挺好。只不过有时候要考虑旧版本的卸载问题,因为客户端技术更新换代,总有技术断层的阶段,旧版本无法正常自动更新到新版。像 Mac 上软件都进到了全局唯一的软件目录,安装时可以由系统来提示,玩 Linux 的也都是大神,安装不上也会自己手动 remove,但最广大的 Windows 用户迫切需要一键卸载旧版本的功能。我找到了 electron-builder 所依赖的 NSIS 安装器,定制了其安装脚本,在检测到旧版本的卸载程序存在于注册表时,会直接调用这个卸载程序,并等待它成功返回后进行新版本的安装过程。
作为互联网产品,诱骗,啊不是,引导用户安装上客户端不是终点,需要推陈出新、高效迭代,这就需要自动更新了。自动更新的目的在于及时让用户用上新版本,仿佛是一句废话。但鉴于大部分用户都是既嫌你更新太勤,又嫌你下载耗费流量,还盼着你能给他一天天地带来体验优化的主,这个开发思路还就是和网页前端不一样。
| 系统 | CPU 架构 | 安装包 | 自动更新包 |
|---|---|---|---|
| Windows | x32 / x64 / arm64 | exe | exe |
| macOS | x64 / arm64 | dmg / pkg | zip |
| Linux | x64 / arm64 | deb / rpm | - |
首先不同的系统当然是不同的包,而根据 CPU 架构及包的用途,就能打出 10 多个不同的安装包来,总大小甚至超过了 2G …… 这在前端的角度看来真有些不可思议,究其原因还是因为 Electron 打包了 Chromium,这个东西就占据了每个安装包中至少 70% 的空间,而这一切都是为了能保证在不同机型上都有一致的浏览体验。
由于一开始开发时没有意料到 CPU 架构竟会如此迅速地扩展,所以现在只得以新版本逐渐刷量的方式来逐步替换成独立架构的客户端。这样做的好处是,后续更新时只需要下载对应架构的文件即可。
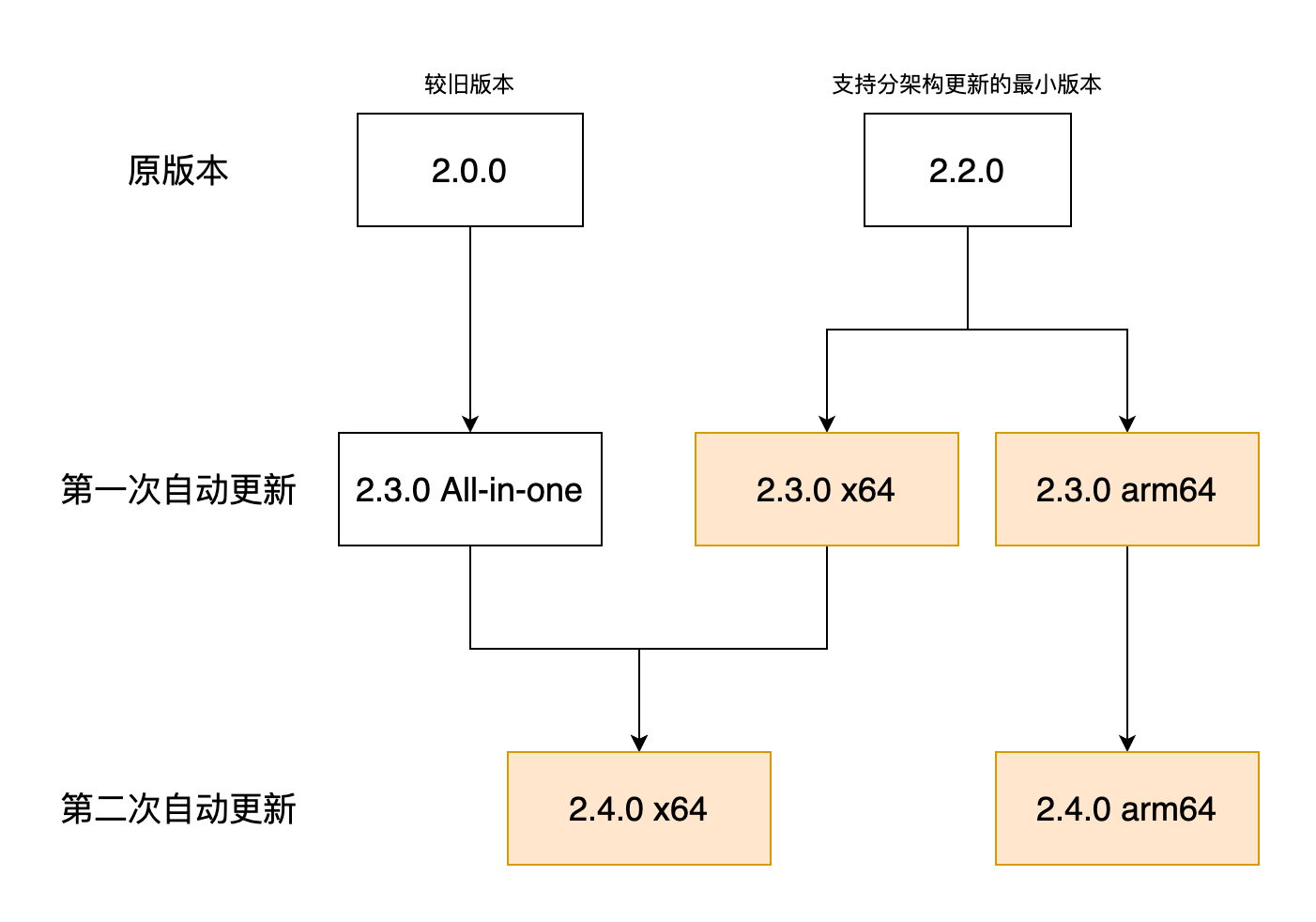
关于自动更新还有如何进行灰度配置下发更新信息,通过 CDN 进行版本管理,App 内如何完成更新等,可参见之前的文章:
这还未到终点,更新一整个客户端接近 100M 的体积仍是过重了,还可以将 Electron 内核和不怎么修改的数据库部分都抽离出来,这样只需要与网页一样更新静态资源即可。
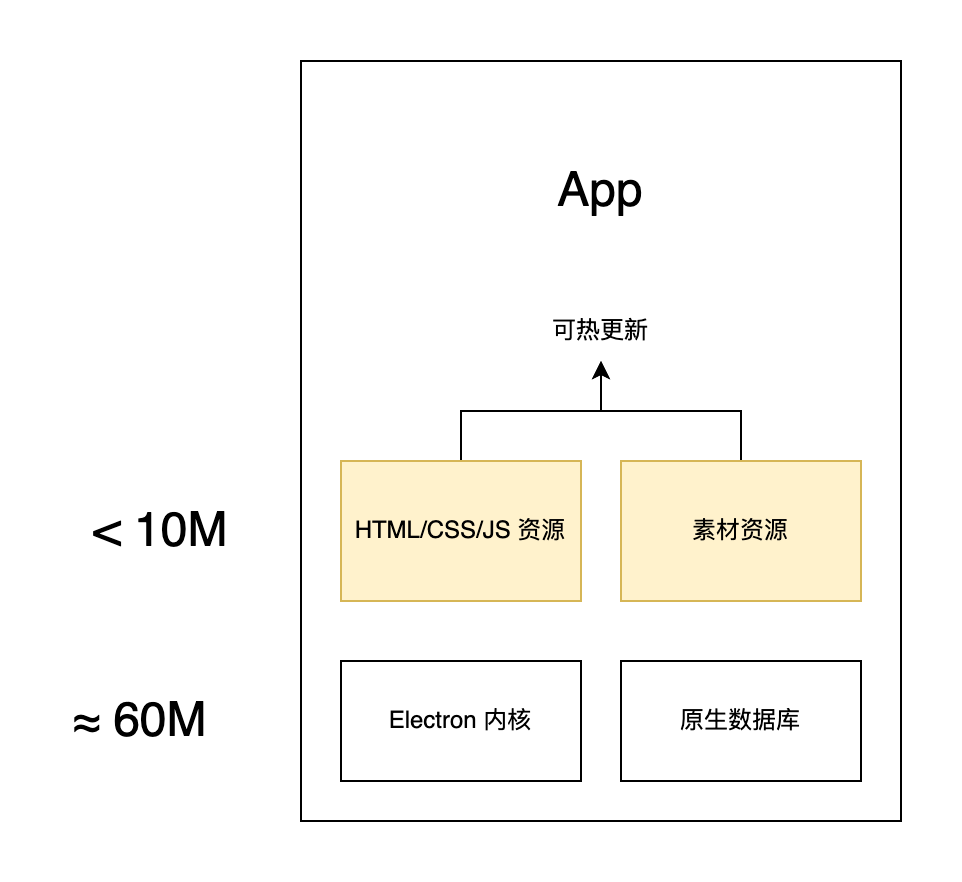
离线使用
本身 Electron 就是可以离线使用的,只是加上了在线网页之后就需要网络才能工作。一种方案是和移动端一样拦截 HTTP 请求并转发到本地离线资源,但这样带来的问题是需要定义非常繁复的拦截规则,以及如何更新离线资源等。
我们可以将离线的数据和资源分离,数据可以同移动端走一套数据库接口,只不过需要将数据库编译成不同的平台的动态链接库。
然后是资源离线使用,或许很多人已经猜到了,那就是被称为 Electron 杀手的 PWA。

在看过了 PWA 所列出的种种好处后,我们发现其不可避免地仍是一个 web 应用。所以,一个大胆的假设,用 PWA 来加载客户端所需要的页面!这样既拥有了网页的便利,又拥有了可触达系统本身 API 的能力,可谓一石二鸟之计。
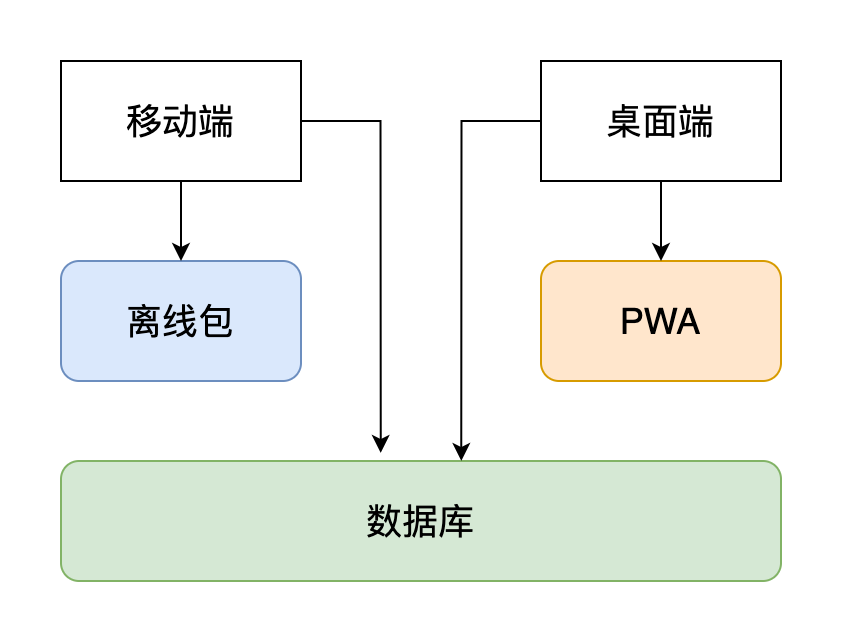
目前我们的腾讯文档桌面端离线功能正在紧锣密鼓地攻坚中,很快将于大家正式见面。
浏览器体验
作为一个名为客户端,实际上是定制版 Chrome 的软件,向 Chrome 看齐永远是对的。
用户说页面字体太小,看不清,那就给他加缩放快捷键。
用户又说缩放了看不到当前比例很慌,那就给他加缩放比例的 tips。

这个用户满意了,那个用户说,哎呀我导出来了文档放在电脑上记不住了呀。
给他抄个 Chrome 的下载记录页面!
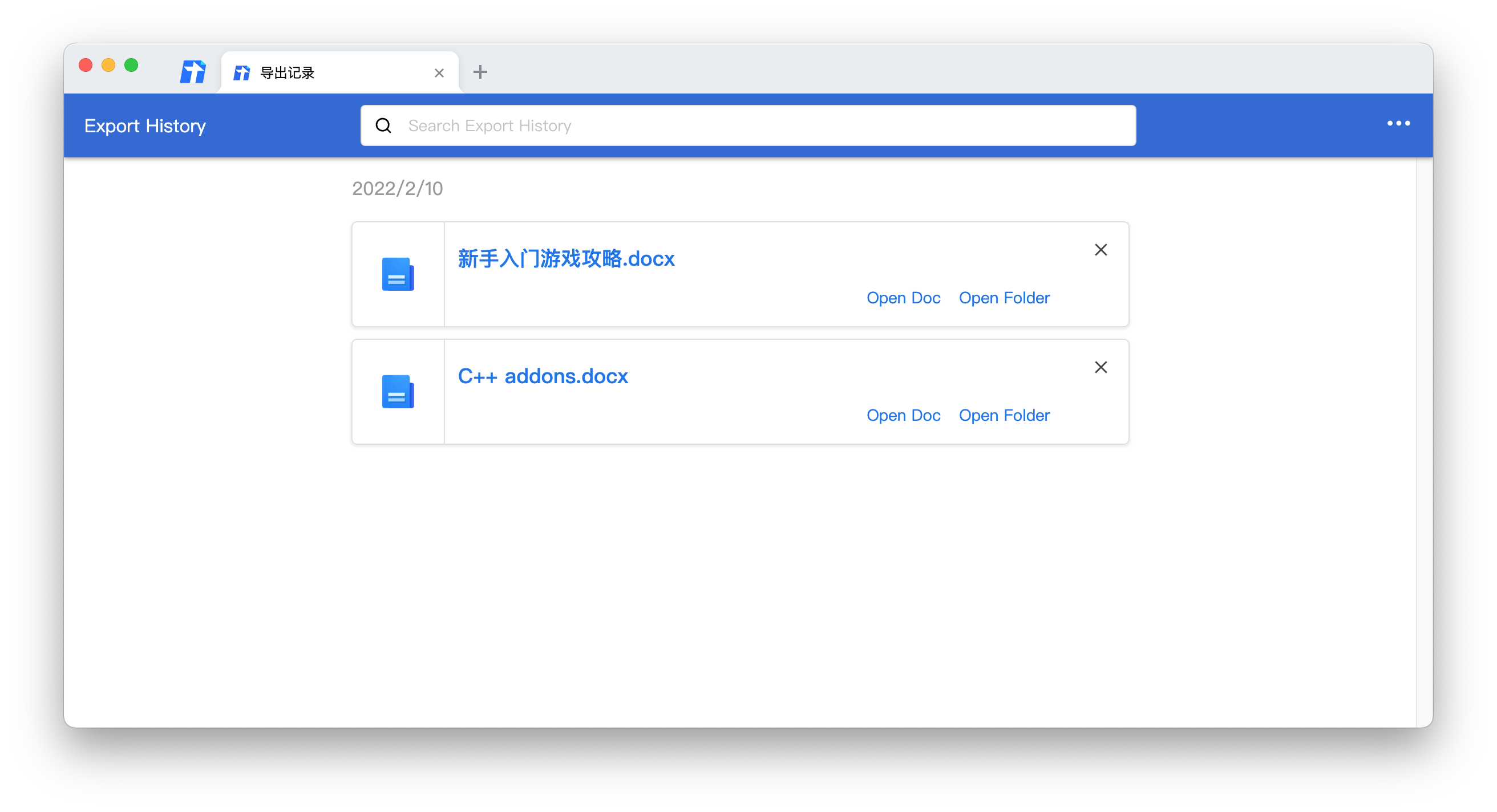
如何存取页面缩放比例?如何在不同窗口间切换时共享一个 tips?鼠标悬浮移入移出 tips 显隐规则是怎样的?
导出记录该如何跟文档一一对应?有很多天记录时该怎么设计数据结构?本地文档被删除了怎么办?
不做不知道,一做吓一跳。原来一个浏览器不止看到的网页部分,周围的配套功能也有很多门道。
作为追赶者,有个好处是毕竟前方一直有领军者,永远有追赶的目标,但也总得想着如何积攒自己的优势,在属于自己的赛道上滑出自己的风采。
角色扮演
前面提到的都是用户需要什么功能,但作为开发不仅仅是写出代码交给用户就完事了,同样重要的是进行多方合作,齐心协力将产品做好。这时就需要发挥主观能动性,在不同的情景下扮演不同的角色了。
测试者
前面提到过,前端页面往往是单个页面完成单个任务,随用随走,所以其测试也主要针对在线数据。但客户端与之不同的在于有本地数据和系统 API 的差异,这也就决定了如果按照传统的人工测试,其成本是很高的。从效能上讲,如果只是编写的代码虽然可以在不同系统运行,但有多少系统就需要测多少遍,是不够经济的,同时测试人员也不一定完全理解设计意图。答案是得用自动化的测试进行覆盖,这就要求开发人员同时扮演测试者的角色。
如何改进呢?首先从技术上讲,应该把测试行为左移。

从设计阶段就应该埋入测试所需的常量或者数据,比如可供 UI 测试获取元素用的 CSS 选择器,一些数据的 mock 可以直接放在类型定义旁边,方便测试时直接引入。
而在编写代码时,则应注意拆分可测试的单元。如果一个功能很复杂,那可以分成若干个子模块来进行编写,同样的,如果一个模块无法便捷地被测试,那它也可以被拆成若干个可测试单元,这样可以在一旦出现问题时通过一系列测试用例,准确定位到具体的单元,而不是一遍遍运行完整的模块测试以查找蛛丝马迹。
在编写测试用例时,区分平台特性是很重要的,例如快捷键或是菜单,这是 mac 和 Windows 存在显著差异的部分,又或者说只支持某个平台的用例,这时就得将不同系统的用例集用不同的机器运行。
到了运行测试时,因为客户端测试往往需要漫长的启动初始化,运行测试,处理异常情况、退出销毁测试环境等过程,在将测试自动化的过程中仍需要缓存一些数据,以供多次运行测试,降低边际成本。
合作方
作为客户端,前端和后端都是你的爸爸。为啥这么说呢?因为页面出了问题,得找前端修,接口出了问题,得找后端修,仿佛变成了 bug 路由器。
想要克服这些问题,需要做到两点:
- 做好日志
当用户发现问题,找到你这边,如何优雅地甩锅 …… 哦不是 …… 定位问题呢?那就是在各种用户行为及接口返回时都做好日志以及进行参数校验,遵循宽入严出的准则。所谓害人之心不可有,防人之心不可无,把任何第三方业务都当成是不可信来源进行防范。同时日志也可以还原出用户操作轨迹,有时候出错的点并不是问题的根源,前几页日志里一行不起眼的 warning 才是真正的问题所在。 - 明确职责
虽然仍然是直面用户的那一端,但团队协作讲究的是分工明确,不逾矩不代劳。客户端本来就是中枢站,如果把前后端的功能都挪到端上实现,必将牵一发而动全身,这就是重构原则里的“发散式变化”。笔者之前接受登录模块,模块里甚至直接存了用户的 token,这是非常敏感的数据,如果不经良好的加密手段,可能造成用户权限被盗用。如何解决这一点呢?答案是不要重复发明轮子,而要善于利用标准轮子。登录相关的标准存储轮子就是 cookie 了,而 cookie 是由 Chrome 直接管辖的,我们只需交给 Chrome 来鉴权,并且自己维护一个非敏感的用户登录状态即可。
如果一段程序不知道其作用范围,那就不要写。
客服
记得我刚毕业实习时问当时 leader,我们会有直面用户的机会吗?leader 微微一笑,肯定会有的。后来我发现,原来不用和用户打交道、安心写代码的日子,才是非常弥足珍贵的……
有人说客服是性子最好的,因为需要每天应对用户各种刁难职责而不变色。当用户找上门来,通常都是丢失了数据、或者打不开应用闪退之类的问题,仿佛落水之人看到了救命稻草。这种情况下,如果不能给用户解决问题,是有很大心理压力的,而人有压力时就容易犯错。
如何降低犯错的概率和风险呢?一种方式是尽量减少操作的步骤。俗话说,less is more,能让用户一键完成的操作就不要让他点两次。
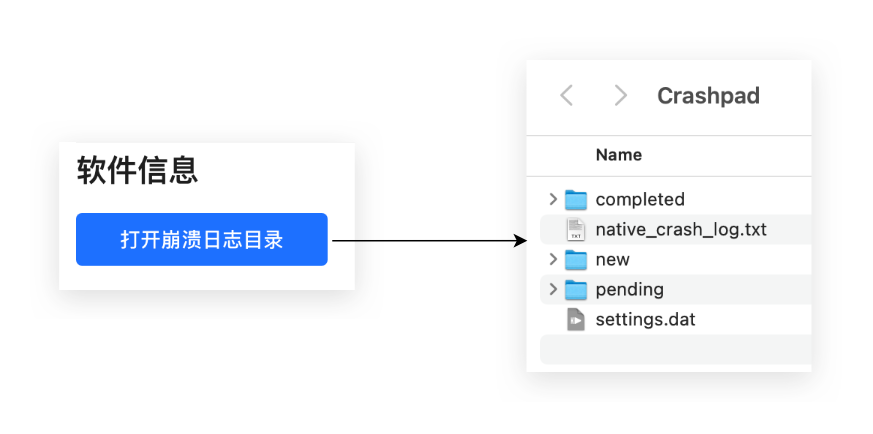
上图是一个打开崩溃日志目录的按钮,用户需要手动把该目录里的 log 文件提供给开发(因为没找到司内相关 native 日志服务)。在没有这个按钮之前,用户需要手动打开终端,输入一长串地址,然后才能到这个目录下,而这中间任何一步都可能阻塞住用户。只有最简单的操作流程,才能高效地解决问题。
但很多时候,用户的问题并不那么简单。看似是 A 除了问题,对比日志后发现 B 也有问题,在 debug B 的过程中发现其依赖于 C。甚至到最后发现这些统统都不是问题所在,用户使用的根本不是你这个软件!这里就陷入了用户给你制造的黑盒。怎么办呢?在现有工具无法保证筛选出正常的反馈时,就得通过作业流程来保证各种类型的 bug 在每个阶段就被精准定位并消灭了。
中医有望闻问切四种基本诊察疾病方法,在针对用户反馈时也可以这么做:
- 望:根据用户描述,大致判断问题是否属于所属产品,是网络问题还是应用问题。
- 闻:故障截图、上报日志,分析可能出错的模块,如若遇到误报情形,在这一步即可排除。
- 问:让用户参与调试,通过改变设置项、清理缓存等步骤以期快速恢复。
- 切:直接给用户换一个版本(客户端就这点好,不同用户可以用着不同版本),相当于做移植手术了。可以植入更多自定义日志上报功能,更全面地分析用户使用状态,以便根治问题。
知识储备
前面讲到了技术应用方向和自我角色扮演,它们都属于外功,也就是技能部分,下面要讲的可说是内功心法。读过武侠小说的人都知道,内外兼修,德才兼备,方可成为一代大师。技巧永远是层出不穷的,只有透过日复一日,年复一年的基础积累,感受技术背后的脉搏,才能融会贯通,成为优秀的开发者。
IPC
Node.js addons
CI 流水线:蓝盾 Stream CI
WebAssembly
模式:图、pub/sub
Windows 注册表
心理建设
采用最通用的技术,延长更迭周期
控制技术的复杂度
学习新技术的恐慌