最近因项目需要开始研究 Node.js 原生模块的实现,并尝试接入自研 C++ 模块。Node.js 因其具有良好的跨平台适配性和非阻塞事件循环的特点,受到了服务端开发者的关注,但 JavaScript 毕竟基于 GC 实现的数据结构,在高性能计算上有所不足;而且很多老代码或者扩展库都以 C++ 书写,也给移植编译带来了一定的困难。如何在性能、兼容性和开发效率上取得平衡,为了解决这些个问题,让我们开始书写第一个 Node.js C++ addon 吧!
C++ addons 的原理 不管你看哪个教程(其实中文书也就一本,就是死月这本《Node.js:来一打 C++ 扩展》 ),提到 Node.js 一上来就是 V8 Isolate, Context, Handle, Scope 讲一堆,看完这两百页头已经晕了。这些都是非常基础的 V8 知识,但离实际运用还隔了很远。为了写出 C++ addons,我们只要抓住一点 ———— “JavaScript 对象就是一个个 V8 C++ 对象的映射”。
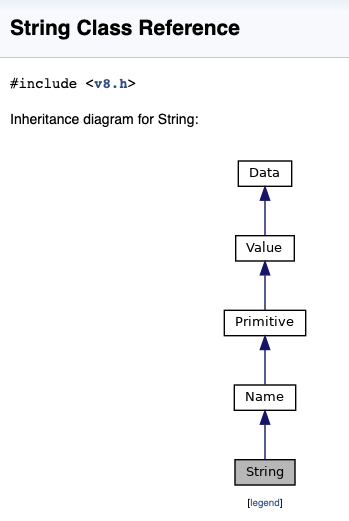
V8
上图是 JS 里一个简单 String 的继承关系,如何创建一个简单的字符串呢?String::NewFromUtf8(isolate, "hello").ToLocalChecked(),是不是看了有些头大?如果告诉你这种继承关系随着 V8 的升级经常发生变化,是不是感觉血压都高了?
没错,这就是上古时期 Node.js C++ addons 的开发方式,需要指定 Node.js 的版本进行编译,只有在指定 ABI 的版本下才能运行。
https://nodejs.org/api/addons.html#hello-world ,有兴趣的读者可以阅读下 Node.js 官网对于 C++ addons 的简易劝退教程,里面展示了不少早期 Node.js 开发者与 C++ 对象搏斗的真实记录。
兼容性 在经历了刀耕火种的日子后,盼星星盼月亮终于迎来了 Node.js 的原生抽象 —— N-API。它利用宏封装了不同 V8 版本之间的 API 差异,统一暴露了多种识别、创建、修改 JS 对象的方法。让我们来看看如何创建一个字符串呢?
1 2 3 4 #include <node_api.h> napi_value js_str; napi_create_string_utf8 (env, "hello" , NAPI_AUTO_LENGTH, &js_str);
哎~ 怎么看起来也不是很简单嘛?。。。
别骂了,别骂了,要知道 Node.js 为了兼容不同版本付出了多大的努力吗?相对来说上述的 API 调用算是很简单的了,最重要的是它很稳定,基本不随着 Node.js 和 V8 的版本更迭而变化。env 是执行的上下文,js_str 是创建出来的 JS 字符串,NAPI_AUTO_LENGTH 是自动计算的长度,这里还隐含了一个变量,就是 napi_create_string_utf8 的返回值 napi_status,这个值一般平平无奇,但万一要是出了 bug 就得靠它来甄别各处调用是否成功了。
C++ addons 实战 前情铺垫结束,让我们拥抱改变吧。下面将带大家以一个简单的 Defer 模块的实现为例,走马观花式感受 C++ addons 的开发过程。
初始化项目 首先你得有个 Node.js,版本呢最好能到 14、16 以上,因为 N-API 有些部分在 14 的时候才加入或者稳定下来。
然后你得准备个 C++ 编译环境,下面简单介绍下各个系统下是如何操作的。
macOS: xcode-select --install 基本可以解决,后面会用 llvm 进行编译。
Windows: 啥都别说了,VS 大法好。推荐装 2019 Community 即可,然后记得把 v142 工具集装了就成。因为 node-gyp 会写死 VS 的版本号,所以如果出了问题就使用 VS installer 继续安装缺失的组件即可。
Linux: apt-get install gcc.
这样就准备好正式编译我们的 C++ addons 了。
node-gyp 通常情况下编译并链接 C++ 库是一件非常吃力不讨好的事,cmake 等工具的出现就是为了解决这个问题,而到了 Node.js 这一边,官方提供了同样的工具 node-gyp。只需 npm i node-gyp -g 即可,后续我们都将在 node-gyp 下操作。
VS Code 相关设置 我们可以在 VS Code 中设置 C++ 环境,这会给开发带来不少的体验提升。https://code.visualstudio.com/docs/languages/cpp
这里是一份可参考的 .vscode/c_cpp_properties.json 示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 { "configurations" : [ { "name" : "Mac" , "includePath" : [ "${workspaceFolder}/**" , "/usr/local/include/node" ] , "defines" : [ ] , "macFrameworkPath" : [ "/Library/Developer/CommandLineTools/SDKs/MacOSX.sdk/System/Library/Frameworks" , "/System/Library/Frameworks" , "/Library/Frameworks" ] , "compilerPath" : "/usr/bin/clang" , "cStandard" : "c17" , "cppStandard" : "c++14" , "intelliSenseMode" : "macos-clang-x63" } , { "name" : "Win32" , "includePath" : [ "${workspaceFolder}/**" , "C:\\Users\\kimi\\AppData\\Local\\node-gyp\\Cache\\16.6.0\\include\\node" ] , "defines" : [ "_DEBUG" , "UNICODE" , "_UNICODE" ] , "windowsSdkVersion" : "10.0.17763.0" , "compilerPath" : "C:/Program Files (x86)/Microsoft Visual Studio/2017/Community/VC/Tools/MSVC/14.16.27023/bin/Hostx64/x64/cl.exe" , "cStandard" : "c17" , "cppStandard" : "c++14" , "intelliSenseMode" : "windows-msvc-x64" } ] , "version" : 4 }
这段 JSON 最重要的就是要指向 node 头文件的 includePath,上面分别提供了当前 Node.js 安装版本和 node-gyp 缓存的路径,以供参考。
Hello world 凡事怎么少得了 hello world 呢?这里假设你已经装好了 node-gyp 了。
先创建一个 main.cpp,写入以下内容。
1 2 3 4 5 6 7 8 9 10 #include <node_api.h> napi_value Init (napi_env env, napi_value exports) { napi_value hello_str; napi_create_string_utf8 (env, "hello" , NAPI_AUTO_LENGTH, &hello_str); napi_set_property (env, exports, hello_str, hello_str); return exports; } NAPI_MODULE (NODE_GYP_MODULE_NAME, Init)
创建一个 binding.gyp,写入以下内容。
1 2 3 4 5 6 7 8 { "targets" : [ { "target_name" : "native" , "sources" : [ "./main.cpp" ] , } ] }
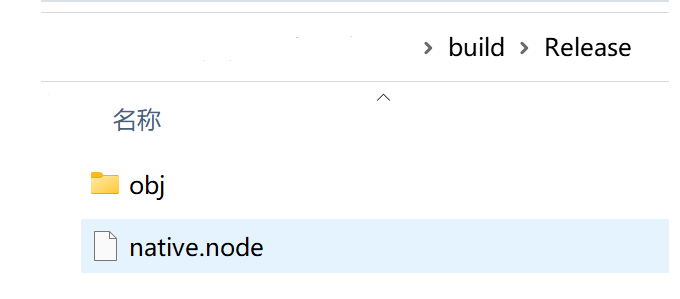
然后执行 npx node-gyp configure build,不出意外的话会生成一个 build 目录,build/Release/native.node 就是我们所要的货了。
如何使用呢?很简单,打开 Node.js REPL,直接 require 就行。
1 2 3 4 Welcome to Node.js v16.6.0. Type ".help" for more information. > require('./build/Release/native' ).hello < 'hello'
大功告成!
小试牛刀:开发一个简单的 Defer 模块 在学习新知识点时,以熟悉的概念切入会更有学下去的动力。我们就小试牛刀,先实现一个非常非常简陋只支持一个 Promise 调用的 Defer 模块吧!
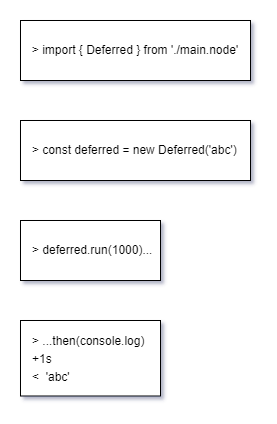
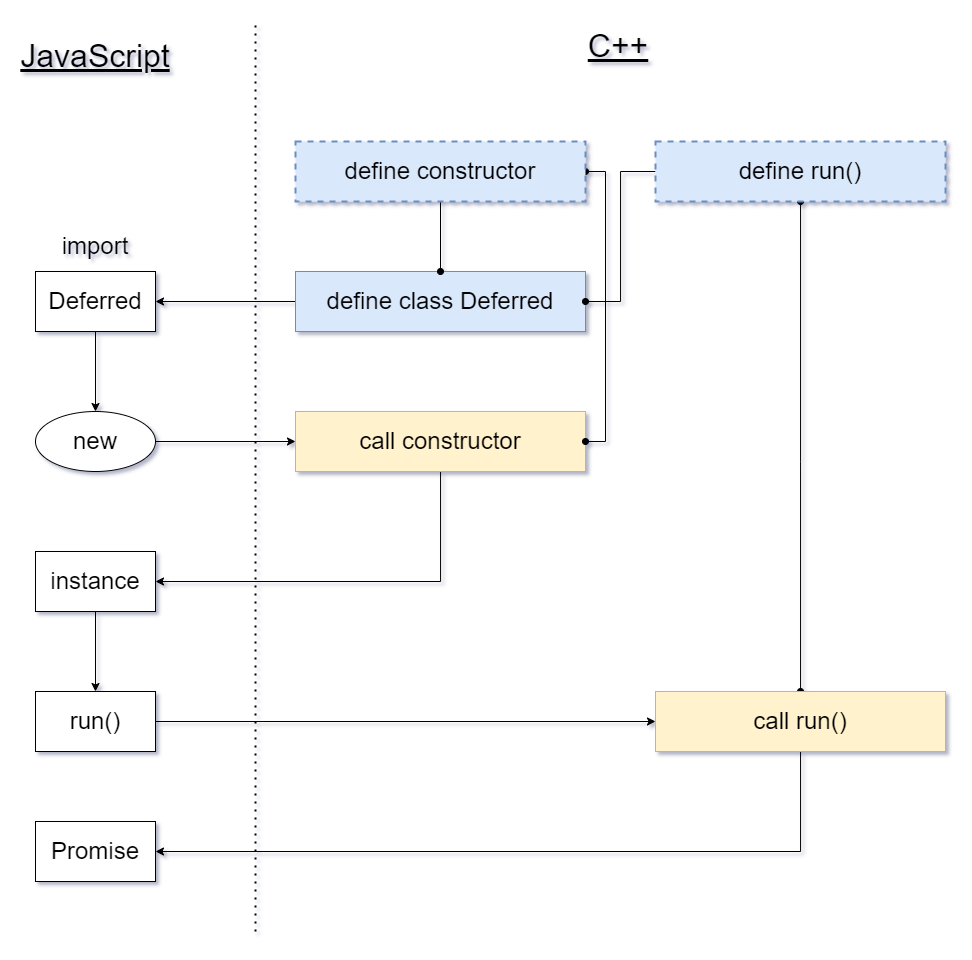
先让我们看一下最终需要的调用方式,从 JS 侧看就是加载一个 *.node 的原生模块,然后 new 了一个对象出来,最后调用一下它的 run 方法。可能 JS 写起来 10 行都不到,但这次的目标是将 C++ 与 JS 联动,这中间的过程就有点让人摸不着头脑了。
别慌,遇事不决先确定接口类型,类型就是编程中的量纲,分析量纲就能得出解题思路。
JS 接口类型定义 抛开语言的差异,来分析一下这个 Deferred 类,它的构造函数接受一个字符串进行初始化,然后有个 public 的 run 方法接受一个数字并返回一个 Promise,以这个数字所代表的毫秒数来延迟 resolve 所返回的 Promise。
1 2 3 4 class Deferred { constructor (private name: string public run (delay : number ): Promise <string > }
咦,这么简单吗?是的,JS 本就为了开发效率而生,但事情整到 C++ 层面可就不那么简单了 …… 但天下大事,必作于细,良好的职责划分有利于用不同的工具切准要害,逐个突破,我们接着往下看。
划分 C++ 与 JavaScript 职责
为了 OOP,我们将数据和行为都存放在一起,这会带来一些问题,就是数据该由谁持有?如果 JS 持有数据,将 C++ 作为一个无状态的服务,每次都将数据从 JS 传过来,计算完了传回去,但这样会造成序列化的开销。如果 C++ 持有数据,JS 侧就相当于一个代理,只是把用户请求代理到 C++ 这一边,计算完再转发给用户侧。
实际情况是,一旦涉及到原生调用,C++ 持有的数据很有可能是 JS 处理不了的不可序列化数据,比如二进制的文件,线程 / IO 信息等等,所以还是 C++ 做主导,JS 只做接口比较好。但这样就不可避免地要从 C++ CRUD 一些 JS 对象了,接着往下走。
创建 C++ 类 激动的心,颤抖的手,终于开始写 C++ 代码了 …… 老规矩,还是先定义一个 class 吧。
1 2 3 4 5 6 7 8 9 10 11 #include <string> #include <functional> #include <node_api.h> class NativeDeferred { public : NativeDeferred (char *str); void run (int milliseconds, std::function<void (char *str)> complete) private : char *_str; };
看起来和 JS 侧的代码也很像嘛,只不过换成了 callback 的方式。如何使它能在 JS 侧使用呢?
创建 JS class
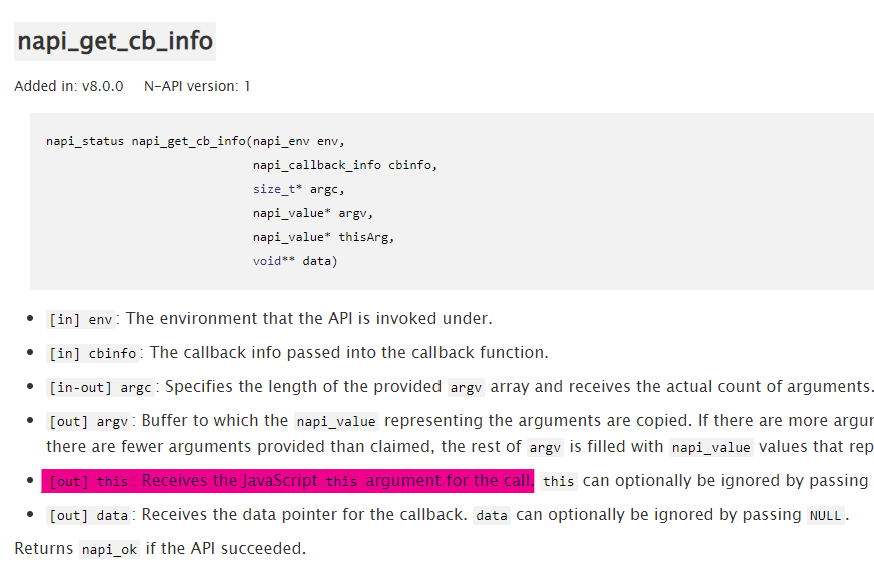
N-API 提供了各种直接创建 JS 对象的方法,包括字符串、数字、undefined 等基本量,也有函数和对象等等。擒贼先擒王,一上来就找到了用于创建 class 的 napi_define_class 。读了一遍定义后,发现需要提供 napi_callback constructor 和 const napi_property_descriptor* properties 作为参数。又马不停蹄地找到了 napi_callback ,这个函数是我们后面会经常遇到的。
napi_callback 接受一个 napi_env 和 napi_callback_info,前者是创建 JS 对象所必须的环境信息,而后者是 JS 传入的信息。
如何解读这些信息呢?有 napi_get_cb_info 这个方法。通过它可以读出包括 this 和各种 ArrayLike 的参数。
我们在讨论如何创建一个 JS 的 class 啊,这是不是绕太远了?等等,你提到了 this?有的面试题里会考如何手写一个 Object.create,难道这就是那里面默认的 this?你猜对了,这个 this 在通过 Function 创建时,在构造器里是用 v8 的 ObjectTemplate 来实例化一个 instance 的。(PS: 如果 napi_callback 是从 JS 侧调用,那它就是 JS 的那个 this。)
从 JS class 创建对象的话,这个 napi_callback 就是 JS 定义的 constructor,执行完返回 this 就行了,但既然是深度融合 C++ 的功能,我们当然还有别的事要做。
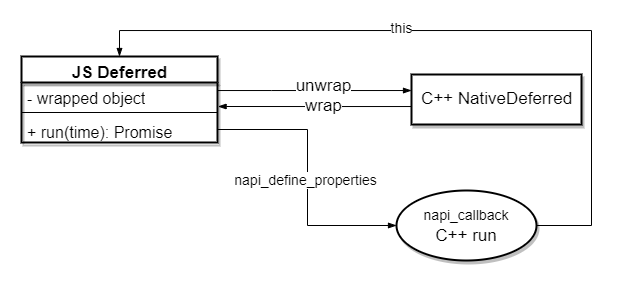
将 C++ 对象封装到 JS instance 上 前面声明了一个非常简易的 C++ 对象 NativeDeferred,我们要将它封装到刚创建的 this 上,返回给 JS 侧。为啥要这样做?因为前面提到了,我们要用 C++ 对象持有一些数据和状态,这些不便于在 JS 和 C++ 来回传递的数据需要一个可追溯的容器来承载(即 NativeDeferred),我们可以假设这个容器有两种存储方式:
全局对象,也就是 V8 里的 global,然后生成一个 key 给 JS instance。
挂到 JS instance 上(N-API 支持这种操作)。
很明显第一种方法不仅污染了全局对象,也避免不了 JS instance 需要持有一个值,那还不如直接把 C++ 对象绑到它上面。
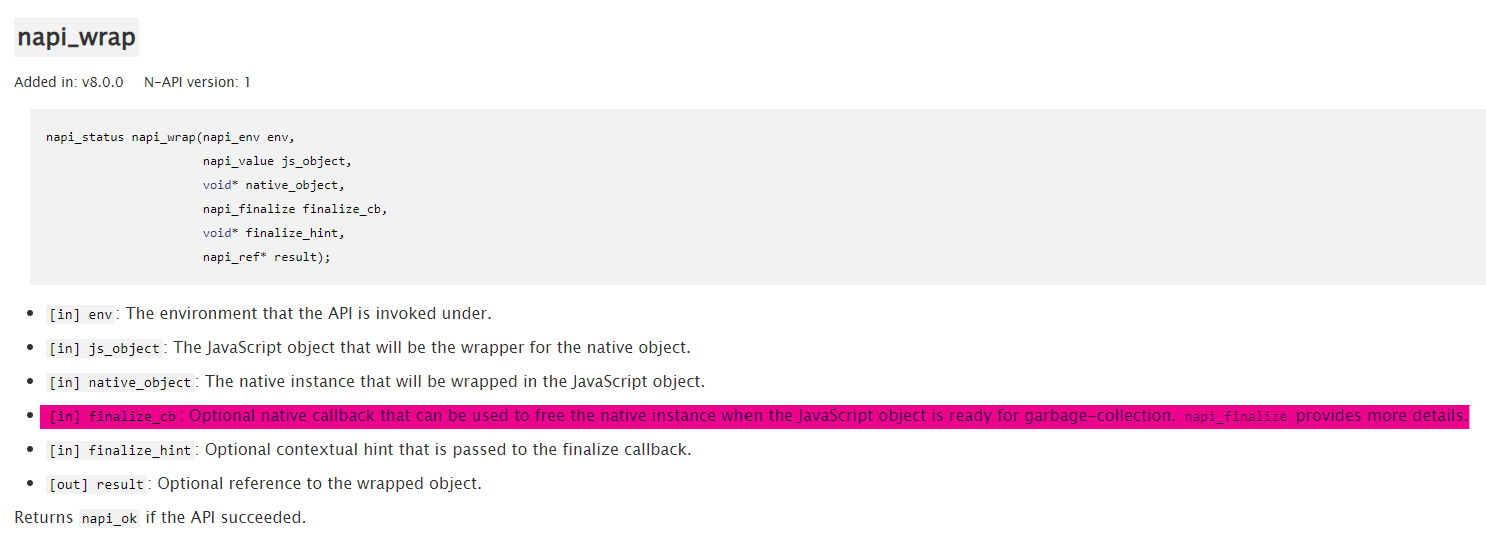
取出 C++ 对象的过程形成了 napi_callback -> JS Deferred(this) -> unwrap C++ NativeDeferred 这样一个线路,需要用到 napi_wrap 和 napi_unwrap 方法。
这里又有个坑,finalize_cb 是必须要赋值的,而且它应该去调用 NativeDeferred 的析构函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 static void Destructor (napi_env env, void *instance_ptr, void * ) reinterpret_cast <NativeDeferred *>(instance_ptr)->~NativeDeferred (); } napi_value js_constructor (napi_env env, napi_callback_info info) NativeDeferred *deferred = new NativeDeferred (name); napi_wrap (env, js_this, reinterpret_cast <void *>(deferred), Destructor, nullptr , nullptr ); return js_this; }
这样,我们就设置好了一个在 constructor 里会生成并自动绑定 C++ 对象的 JS class。
设置 JS class 上的调用方法 数据只有实际被使用才能发挥其价值,对应到 JS Deferred 上面,就是要让 JS 侧 run 方法顺利地调用到 C++ 侧的 run,这里面又要经历前面所说的从 napi_callback 一直到拿到原生 NativeDeferred 的过程,但如何让这个 napi_callback 可以被 Deferred 实例后的对象应用呢?
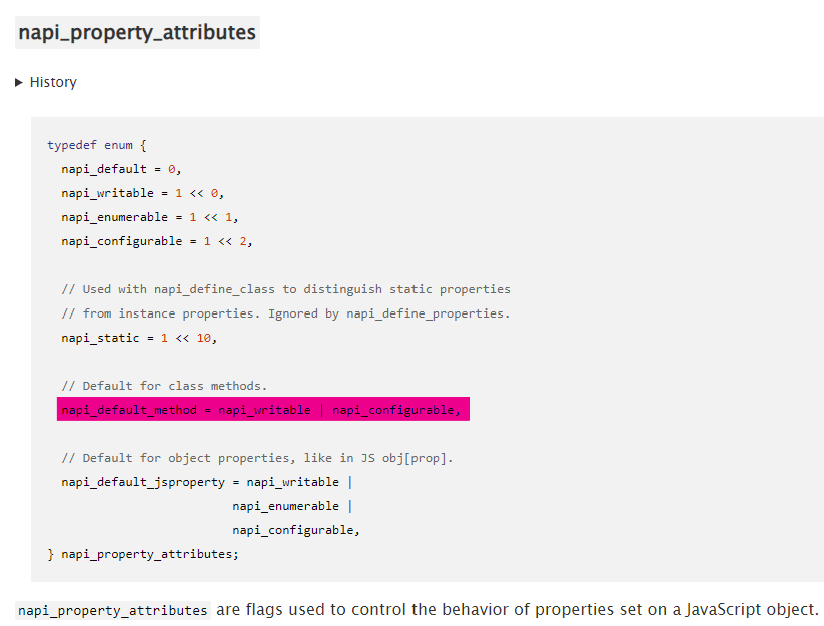
聪明的读者已经猜到了,就是将它设到 Deferred 这个类的原型链上,具体来说就是前面 napi_define_class 时的 const napi_property_descriptor* properties,我们来看一下它的定义。
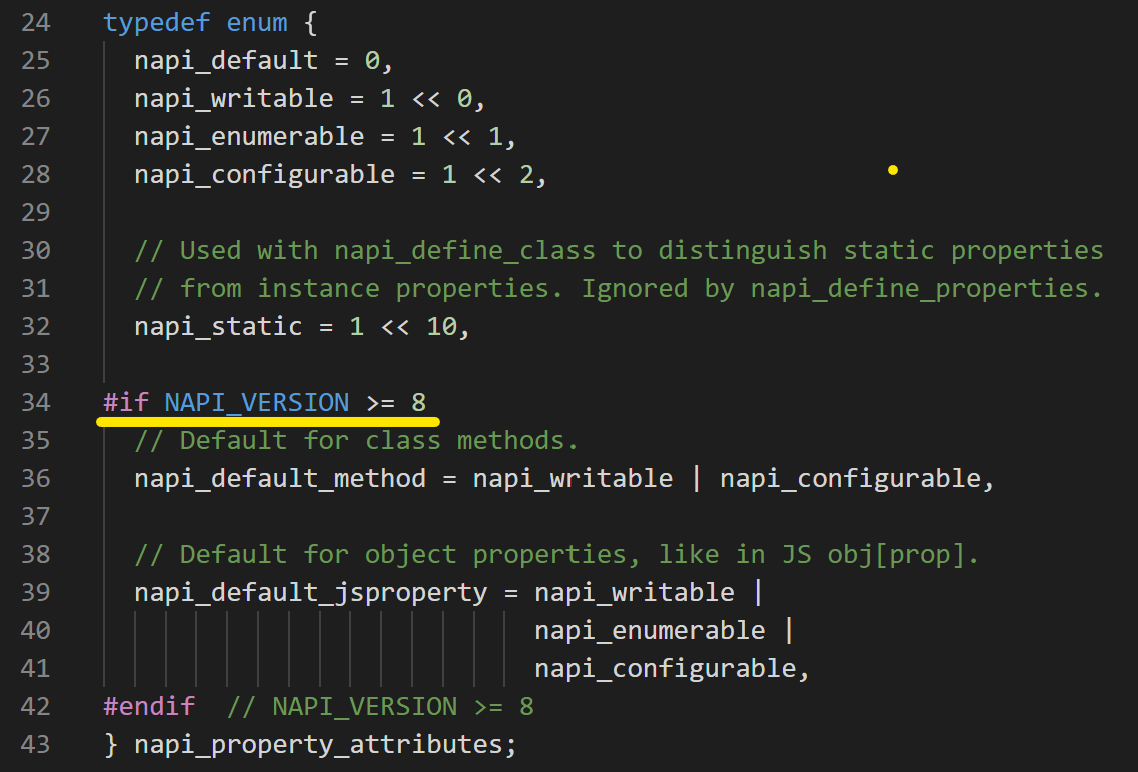
napi_property_descriptor 上其他属性都比较常见,似乎跟 Object.defineProperty 有些相似,但 enumerable 和 configurable 这些值呢?。我们注意到了 napi_property_attributes 这个参数,
找到了找到了,这就是我们需要的属性了。
1 2 3 4 5 6 7 8 9 #include <node_api.h> napi_property_descriptor runDesc = {"run" , 0 , js_run, 0 , 0 , 0 , napi_default_method, 0 }; napi_value js_class; napi_property_descriptor descs[1 ] = {runDesc}; napi_define_class (env, "Deferrered" , NAPI_AUTO_LENGTH, js_constructor, nullptr , 1 , descs, &js_class);
*js_run 会在下一节实现。
上面的 js_class 就是我们一开始定义的 JS Deferred 了,将他 napi_set_property 到 hello world 中的 exports 上就能被 Node.js 访问啦。
这里还有个坑,napi_default_method 有些版本下是被定义在 if 里的,需要我们预先 define NAPI_VERSION 或者 NAPI_EXPERIMENTAL。
让我们打开 binding.gyp,在 target 里加入以下内容,就可以啦。
1 2 3 4 5 6 { "defines" : [ "NAPI_EXPERIMENTAL" , "NAPI_VERSION=8" , ] , }
C++ 回调 JS callback 到现在我们已经实现了一个 class 所需要的一切能力,但有个小问题:这些方法都是单向的从 JS 侧传递给 C++ 侧,或者反之,没有双向交互的部分。可以想一想怎样算是“双向交互”呢?就是 Node.js 常见的 callback 啊,我们还没有涉及到如何从 C++ 调用 JS 函数。napi_call_function 这个函数就是 napi_get_cb_info 的逆操作了,把参数按个数和数组传递给函数指针。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 napi_value fire_js_callback (napi_env env, napi_callback_info info) { napi_value js_this; napi_value args[1 ]; size_t argc = 1 ; napi_get_cb_info (env, info, &argc, args, &js_this, nullptr ); napi_value num; napi_create_int32 (env, 42 , &num); napi_value res[1 ] = { num }; napi_call_function (env, js_this, args[0 ], 1 , res, nullptr ); return num; }
总结一下,我们目前总共实现了以下的 C++ addon 能力。
功能
实现
创建 JS class
✅
给 JS class 添加 method
✅
将 C++ 对象封装到 JS 对象上
✅
调用 JS 函数
✅
高级技巧 读到这里的朋友可能发现了,前面提到的 Deferred 还有一环没有实现,就是延时调用。来想一下 C++ 里如何能延时呢?可以另外启动一个线程,将它 sleep,可以简单写下代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <node_api.h> #include <thread> #include <functional> static void thread_run (std::function<void ()> complete) std::this_thread::sleep_for (std::chrono::milliseconds (1000 )); complete (); } napi_value fire_js_callback (napi_env env, napi_callback_info info) { napi_value js_this; napi_value args[1 ]; size_t argc = 1 ; napi_get_cb_info (env, info, &argc, args, &js_this, nullptr ); napi_value num; napi_create_int32 (env, 42 , &num); napi_value res[1 ] = { num }; std::function<void ()> complete = [=]() { napi_call_function (env, js_this, args[0 ], 1 , res, nullptr ); }; std::thread runner (thread_run, complete) ; runner.detach (); return num; }
但实际调用时,等了很久也没有触发,这是为什么呢?
JavaScript functions can normally only be called from a native addon’s main thread. If an addon creates additional threads, then Node-API functions that require a napi_env, napi_value, or napi_ref must not be called from those threads.
When an addon has additional threads and JavaScript functions need to be invoked based on the processing completed by those threads, those threads must communicate with the addon’s main thread so that the main thread can invoke the JavaScript function on their behalf. The thread-safe function APIs provide an easy way to do this.
Asynchronous thread-safe function calls
原来跨线程之后 napi_env 就不是原来的那个它了,我们需要按照 N-API 的方式来包装一下异步调用的函数。
线程安全调用 写到这里,笔者发现自己的功力已经不足以解释我所看到的文档了,直接上代码吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include <node_api.h> #include <thread> #include <functional> static void thread_run (std::function<void ()> complete) std::this_thread::sleep_for (std::chrono::milliseconds (1000 )); complete (); } static void thread_callback (napi_env env, napi_value js_callback, void * context, void * data) napi_value js_this = reinterpret_cast <napi_value>(context); napi_value num; napi_create_int32 (env, 42 , &num); napi_value res[1 ] = { num }; napi_call_function (env, js_this, js_callback, 1 , res, nullptr ); } napi_value fire_js_callback (napi_env env, napi_callback_info info) { napi_value js_this; napi_value args[1 ]; size_t argc = 1 ; napi_get_cb_info (env, info, &argc, args, &js_this, nullptr ); napi_value async_resource_name; napi_create_string_utf8 (env, "foobar" , NAPI_AUTO_LENGTH, &async_resource_name); napi_threadsafe_function thread_complete; napi_create_threadsafe_function ( env, args[0 ], nullptr , async_resource_name, 0 , 1 , nullptr , nullptr , js_this, thread_callback, &thread_complete); std::function<void ()> complete = [=]() { napi_call_threadsafe_function (thread_complete, nullptr , napi_tsfn_blocking); }; std::thread runner (thread_run, complete) ; runner.detach (); return js_this; } napi_value Init (napi_env env, napi_value exports) { napi_value fire_str; napi_create_string_utf8 (env, "fire" , NAPI_AUTO_LENGTH, &fire_str); napi_value fire; napi_create_function (env, "fire" , NAPI_AUTO_LENGTH, fire_js_callback, nullptr , &fire); napi_set_property (env, exports, fire_str, fire); return exports; } NAPI_MODULE (NODE_GYP_MODULE_NAME, Init)
经过一番眼花缭乱的操作后,终于成功触发了 args[0] 处的 JS callback 函数,这就是简化版本的 js_run 了。
Promise 的实现 既然实现了异步回调,我们再努力一把,实现 Promise 的返回值,这就比较简单了,N-API 将 napi_create_promise 设计为生成 napi_deferred* deferred 和 napi_value* promise,一式两份,一份直接返回给 JS,一份则留着在异步调用中将其 resolve。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 static void thread_callback (napi_env env, napi_value js_callback, void * context, void * data) napi_deferred deferred = reinterpret_cast <napi_deferred>(data); napi_value num; napi_create_int32 (env, 42 , &num); napi_resolve_deferred (env, deferred, num); } napi_value fire_js_callback (napi_env env, napi_callback_info info) { napi_value js_this; size_t argc = 0 ; napi_get_cb_info (env, info, &argc, nullptr , &js_this, nullptr ); napi_value async_resource_name; napi_create_string_utf8 (env, "foobar" , NAPI_AUTO_LENGTH, &async_resource_name); napi_threadsafe_function thread_complete; napi_create_threadsafe_function ( env, nullptr , nullptr , async_resource_name, 0 , 1 , nullptr , nullptr , nullptr , thread_callback, &thread_complete); napi_value promise; napi_deferred deferred; napi_create_promise (env, &deferred, &promise); std::function<void ()> complete = [=]() { napi_call_threadsafe_function (thread_complete, deferred, napi_tsfn_blocking); }; std::thread runner (thread_run, complete) ; runner.detach (); return promise; }
篇幅起见,只贴出关键的两个函数了。
完工 事已至此,与 Deferred 这个类相关的代码已经基本介绍完了,完整的代码可以参见这个仓库:https://github.com/msyfls123/basin
启动工程应该只需要:
1 2 3 4 npm i npm run configure npx node-gyp rebuild --debug npm run basin
C++ addons 调试与构建 别看前面洋洋洒洒一堆操作,只写出了百来行代码,基本每行代码都踩过坑。这时候强有效的调试工具就显得非常重要了。
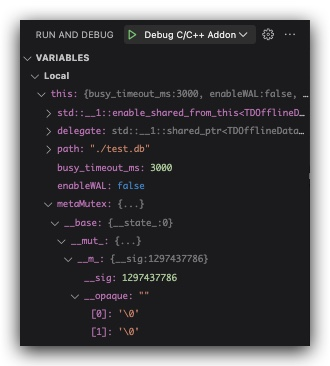
VSCode CodeLLDB 调试 推荐大杀器 CodeLLDB ,配合 launch.json 食用,可在 VSCode 中左侧 Run and Debug 里对 C++ 代码断点并显示变量信息。
简易 launch.json
1 2 3 4 5 6 7 8 9 10 11 12 13 { "version" : "0.2.0" , "configurations" : [ { "name" : "debug with build" , "type" : "lldb" , "request" : "launch" , "preLaunchTask" : "npm: build" , "program" : "node" , "args" : [ "${workspaceFolder}/index.js" ] } , ] }
prebuildify 预构建包 前面都是开发模式,如果是服务端使用的话,加上入口 js 文件后已经可以作为 npm 包发布了,安装时会自动执行 node-gyp rebuild 重新构建的。
常见架构有:
Linux: x64, armv6, armv7, arm64
Windows: x32, x64, arm64
macOS: x64, arm64
竟然有这么多 …… 还好社区提供了跨平台编译的解决方案 ———— prebuild,但它需要在安装时下载对应的包,所以还需要将这些构建产物发布到服务器上,不与 npm 包放在一起。虽然在包体积很大的情况下的确有必要,这显然不是我们所追求的一键下载。
然后我就找到了 prebuildify 。它是这么说的:
With prebuildify, all prebuilt binaries are shipped inside the package that is published to npm, which means there’s no need for a separate download step like you find in prebuild. The irony of this approach is that it is faster to download all prebuilt binaries for every platform when they are bundled than it is to download a single prebuilt binary as an install script.
Always use prebuildify --@mafintosh
有没有成功案例呢?有,那就是 Google 出品的 LevelDB 的 js 封装 就是它做的,
我们项目里也应用了这个方案,参见 https://github.com/msyfls123/basin/blob/main/package.json#L16-L18。
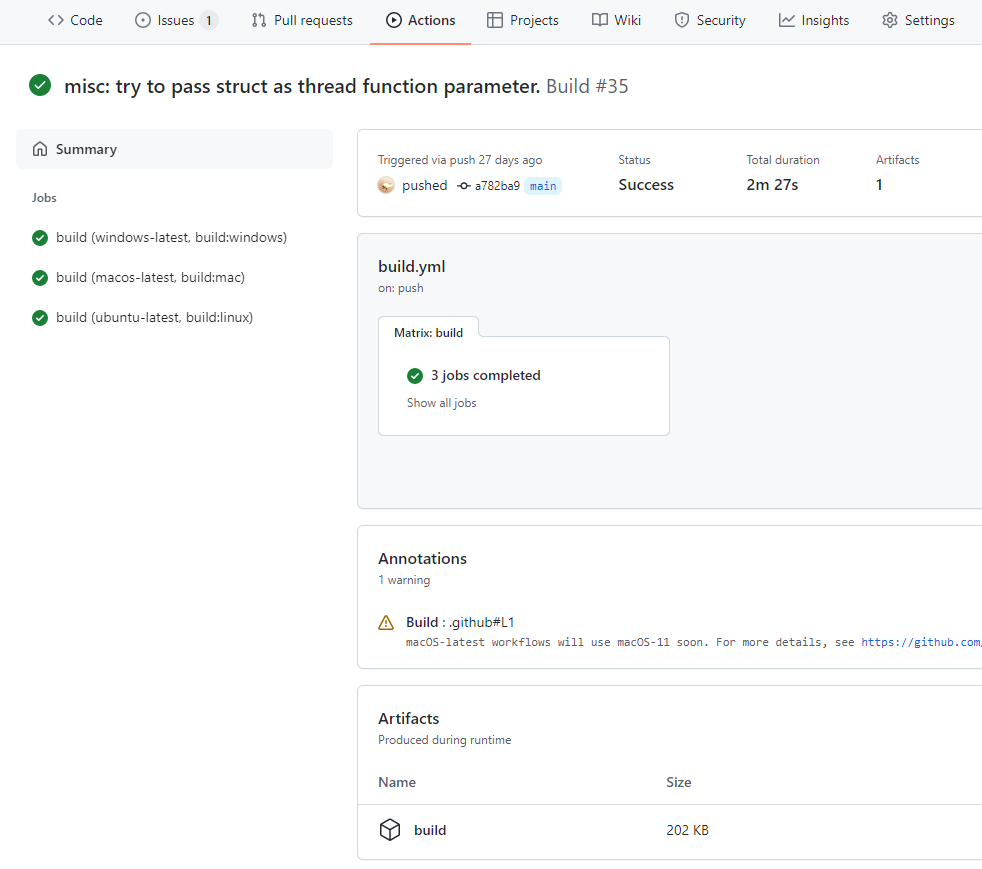
与 CI 集成 可是这虽然可以只在三个系统各执行一遍进行编译,但每次发布都得登录三台机器来执行吗?no, no, no, 我们当然可以将这一切集成到 CI 中自动运行。
这里展示一下业界标杆 ———— GitHub Actions 的配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 name: Build on: push jobs: build: runs-on: ${{ matrix.platform.runner }} env: CXX: g++ strategy: matrix: platform: [ { runner: "windows-latest" , command: "build:windows" }, { runner: "macos-latest" , command: "build:mac" }, { runner: "ubuntu-latest" , command: "build:linux" }, ] fail-fast: false steps: - name: Check out Git repository uses: actions/checkout@v2 - name: Set up GCC uses: egor-tensin/setup-gcc@v1 with: version: latest platform: x64 if: ${{ matrix.platform.runner == 'ubuntu-latest' }} - name: Install Node.js, NPM and Yarn uses: actions/setup-node@v2 with: node-version: "16.6.1" - name: Install Dependencies run: | npm i --ignore-scripts - name: Compile run: | npm run configure npm run ${{ matrix.platform.command }} - name: Archive debug artifacts uses: actions/upload-artifact@v2 with: name: build path: | index.js index.d.ts package.json prebuilds/
C++ addons 的展望 至此,本文也要进入尾声了,期望能对想要提升 Node.js 程序性能或是拓展应用场景的你带来一些帮助!最后提两点展望吧:
无痛集成第三方库 笔者看到项目里大部分第三方 C++ 库都是以源码形式引入的 …… 对于习惯 npm i 的人来说这肯定是像狗皮膏药一样贴在心上。听说 bazel 挺香,但其语法令人望而却步,似乎也不是一个依赖管理工具,这时有个叫 Conan 的货映入眼帘。
这里有篇文章讲述如何将 Conan 和你的 Node.js addons 结合,笔者试了一下确实可行,甚至都不需要 python 的 virtualenv,只是 libraries 需要小小的调整下:
1 2 3 'libraries': [ "-Wl,-rpath,@loader_path/" ]
编译目标:WebAssembly Interface? 居安思危,笔者也思考了下 Node.js addons 的局限性,需要每个平台都编译一遍还是有点麻烦的,有没有什么办法可以 compile once, run everywhere 呢?
有!那就是 WebAssembly,“那你为啥不用呢?”,这是个好问题。LevelDB 仓库内也有过类似的讨论 ,最后问题落到了性能和文件系统上,如果涉及到异步线程问题的话,会更复杂一点,因为 emcc 的 pthread 是基于 Web Worker 提供的,不清楚 Node.js 侧是否有 polyfill,以及在不同 Worker 运行,各种同步原语、Arc、Mutex 等是否都得到了支持,这些都是未知的。所以遇到一坨祖传下来打满了补丁的 C++ 代码,我们选择的稳妥方式依然是悄悄关上门,然后建座桥,把路直接修到它门口就跑,真刺激啊……