为什么我们要打包源代码
盘古开天之际,我们是不需要打包代码的,直接执行即可……
咳咳,走错片场了。但道理是一样的,当计算机还是由纸带驱动时,什么程序和数据都是混杂在一个个空洞之上,像挂面一样,没法打包,或者说压缩。直到区分了处理器和存储器,才有了汇编指令,程序才变得像意大利面一样曲曲折折,千转百回。
今天我们组的实习生突然提到了 B/S 架构,突然联想到之前的单体发布应用,加上目前对于 WebAssembly 等胶水层和大大小小各种容器技术的理解,想对编译打包这个过程做一点分析。任何产品,哪怕是数字产品,所追求的永远是多快好省,在更新频率要求很低的 90 年代,发放软件的方式可以是光盘💿甚至软盘💾,每次更新升级都需要插入磁盘驱动执行更新程序,这在当下点一点就能升级的体验是天壤之别了。用户的体验升级也意味着开发模式的进步,从复杂的单体架构(dll -> exe),变成了松散分布的依赖包共同组织成一个完整的应用(npm -> exe)。甚至无代码开发的时候,某些重型库或包的大小已经超出了一般的应用程序,这时如何将它们有机地组合在一起,将不多也不少刚刚好的应用交付给用户,就成了开发人员需要解决的难题。
熟悉前端的朋友应该知道,JavaScript 的加载经历了纯 script 引用加载 - AMD 异步依赖的刀耕火种时期,直到 2012 年 Webpack 横空出世,才解决了打开一个页面需要加载成千上百个 js 文件的困境。这是 HTTP 1.x 的弊病所导致的,当然这个时期 JavaScript 的作用大多限于提升页面丰富度,随着 node.js 的应用,越来越多的与系统相关的包进入 npm,它们活跃在 node.js 层,却无法被浏览器使用,怎么办呢?一个办法是在浏览器里模拟操作系统,就是虚拟机,这个肯定性能有问题,pass,或者就是把系统相关的接口阉割掉,只保留计算部分,这就是 WebAssembly:将程序编译成字节码在浏览器里以汇编运行,实现了浏览器编译能力的升华;另一个办法,是把浏览器和 node.js 环境捆绑打包起来,这就是 Electron!
个人觉得 Electron 最精髓的应用不在于可以把网页打包成桌面应用,当然也是赋予了它很多桌面应用才有的功能,比如数据库以及和系统交互的能力。最重要的是引入了 B/S 架构以后,代码的打包阶段可以被分块分层,从而使开发和构建过程各取所需,一个预想的未来是可以基于 Electron 做下一代编辑器(Visual Studio Code++ …… 大误,逃)集成了从服务端到浏览器端的全链路。当然目前比较有用的是可以选择性地不打包一些库。
开发时工具不用打包
用于开发时自动重启的 electron-connect 是不用打包到生产环境的。可通过配置
1 | // main-process/window |
1 | // rollup.config |
来避免打包,在开发环境里用 node_modules 里的就好啦。
重型依赖只在生产环境下打包
像 RxJS 这种重型依赖,编译打包一遍耗时巨大,我们可以把它也排除在外,具体配置如下
1 | // rollup.config |
开发环境打包流程如下:
- copy node_modules 下的 rxjs umd 文件至输出目录
- 渲染进程打包文件,排除掉 rxjs,并设置其为全局依赖(window.rxjs)
- 在 html 中引入拷贝过去的 umd 文件
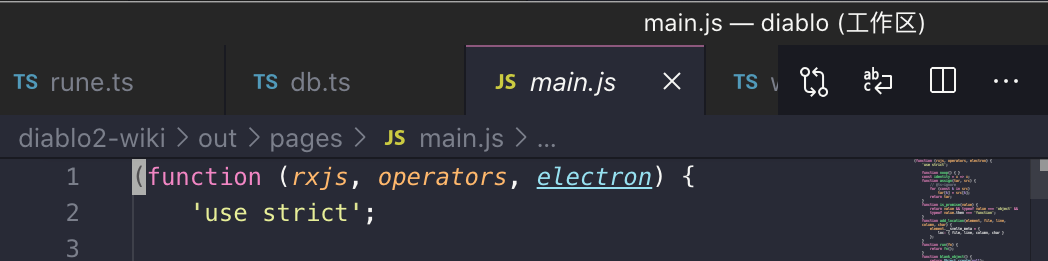
避免无谓的打包,把优化用在刀刃上
这样以后,开发环境将不在打包 rxjs,而生产环境下做 tree-shaking 之后直接和业务代码合成一块,在本机加载的基础上更进一步缩小体积,利于解析。实际上,Electron 将大部分的包都直接打进 exe 文件都不会太大影响,只是为了项目目录整洁,我们还是选择尽可能多的用 bundle 过的包,无论是 npm 打包的还是我们自己 bundle 的。