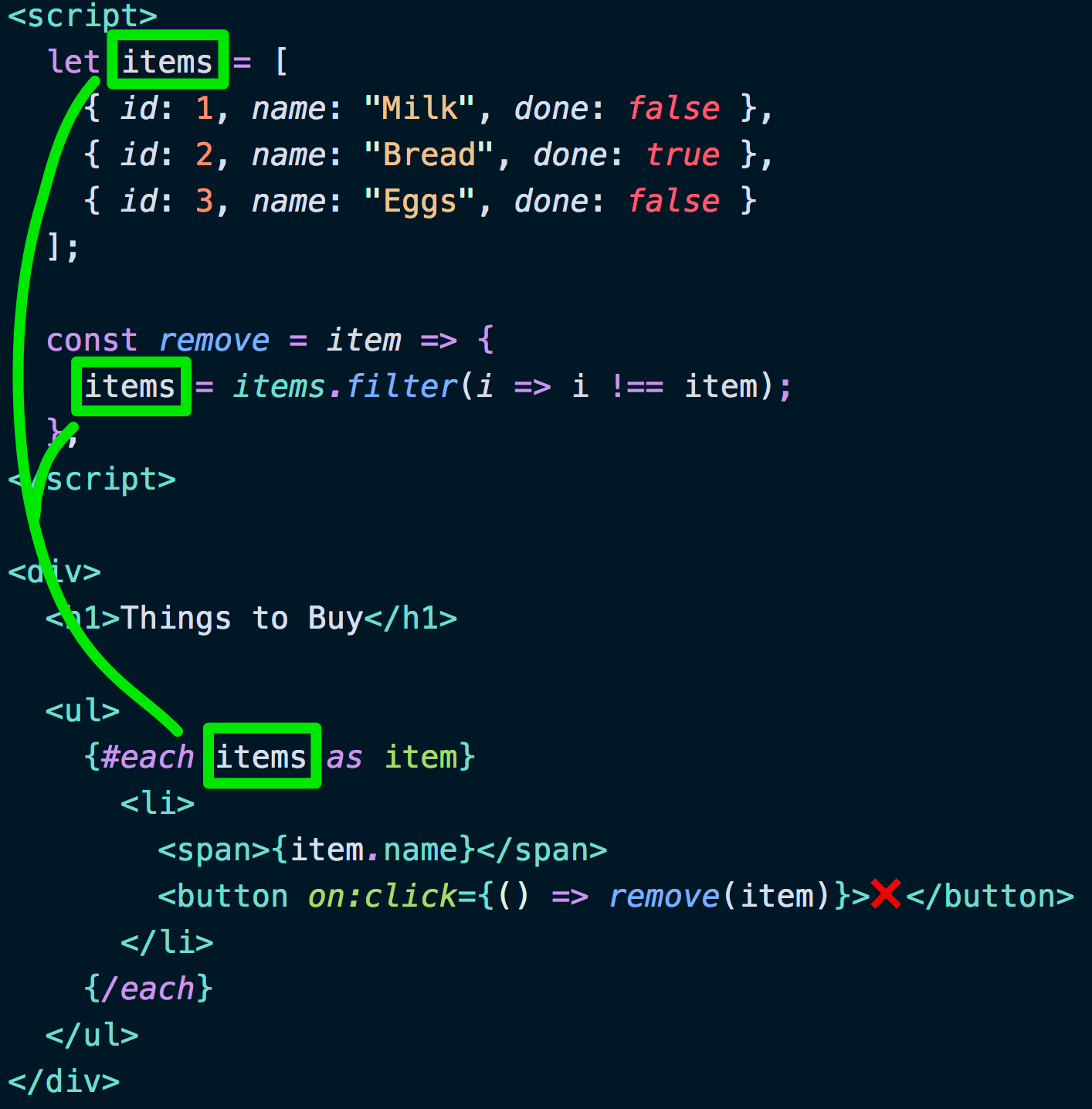
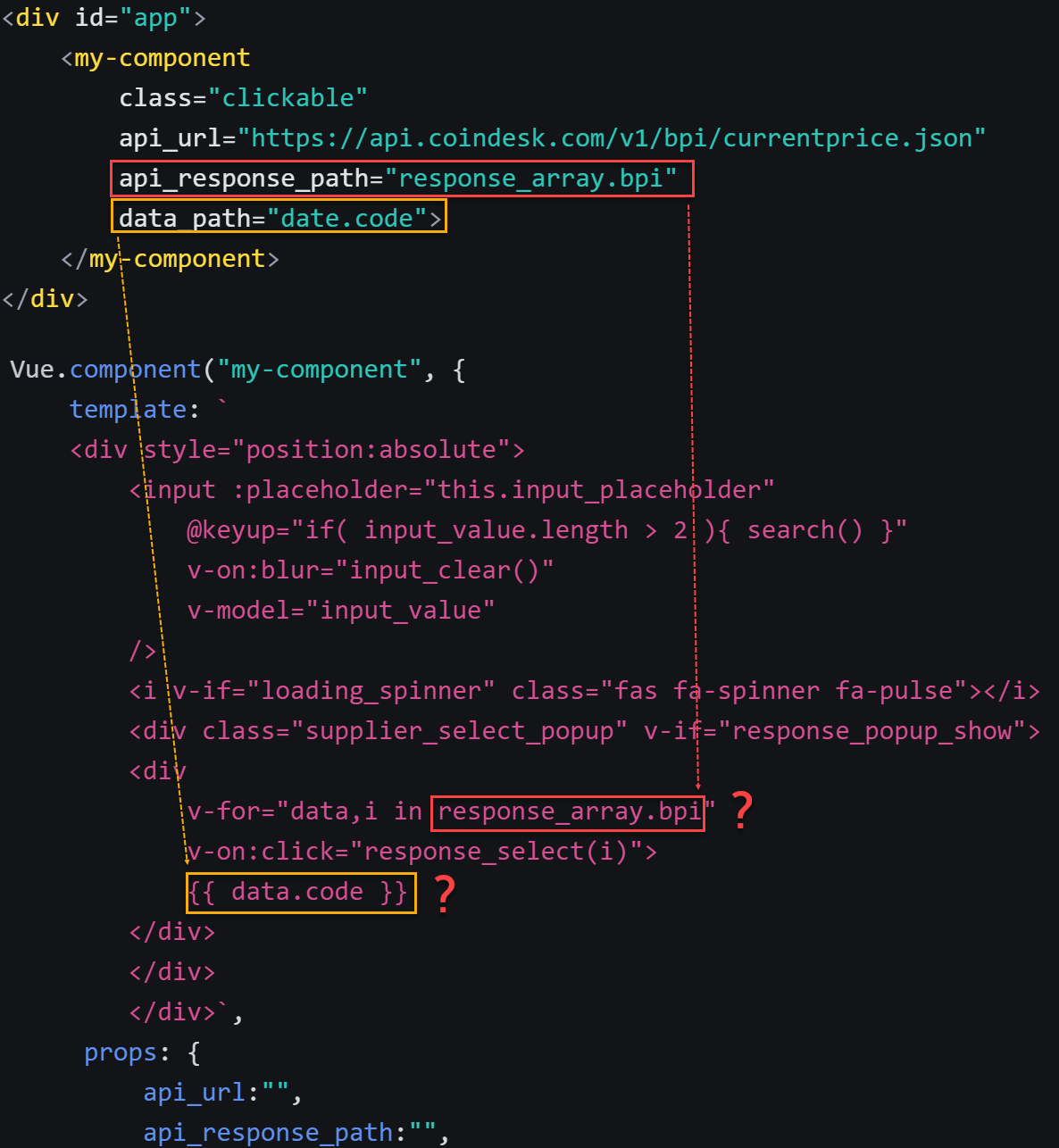
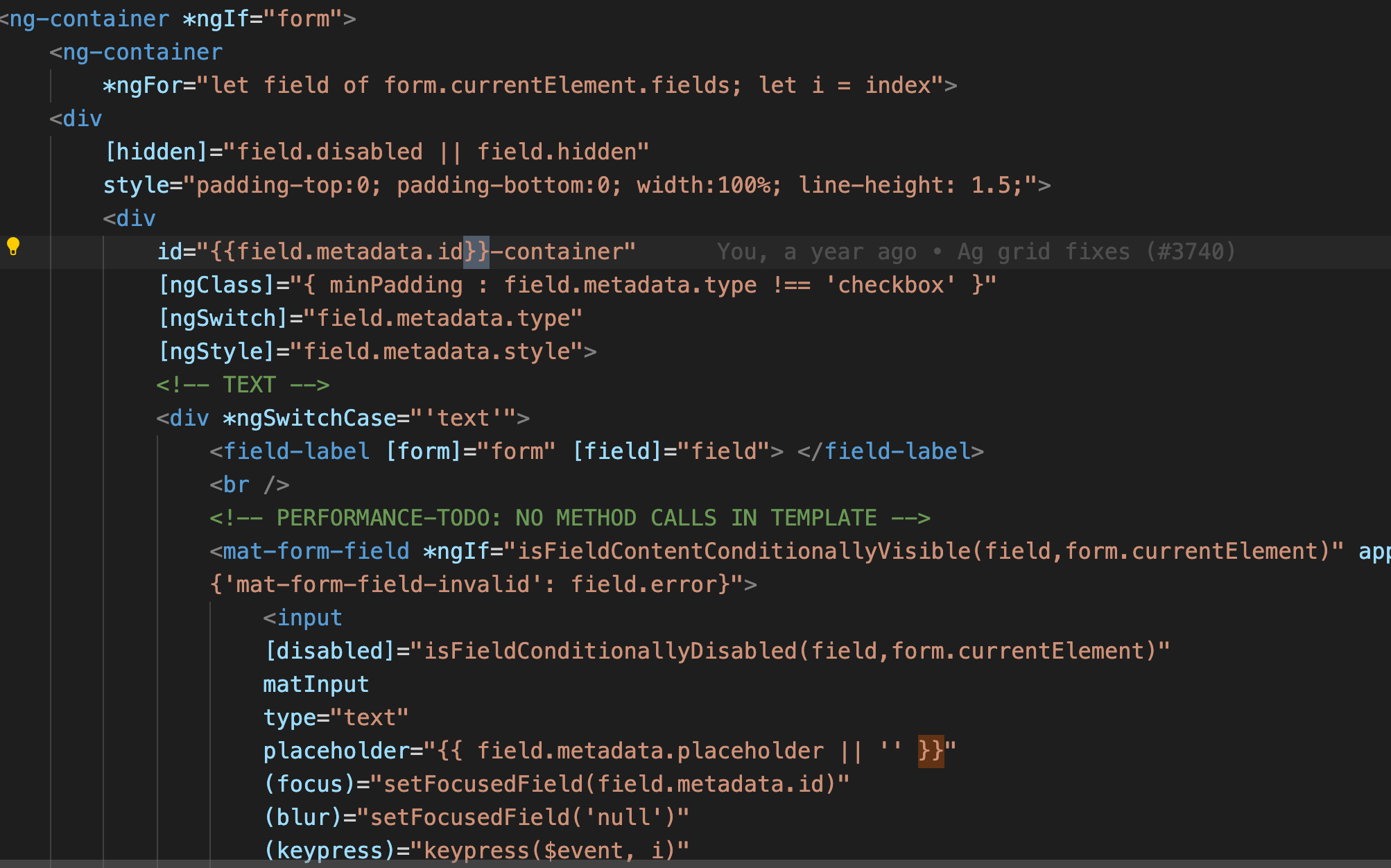
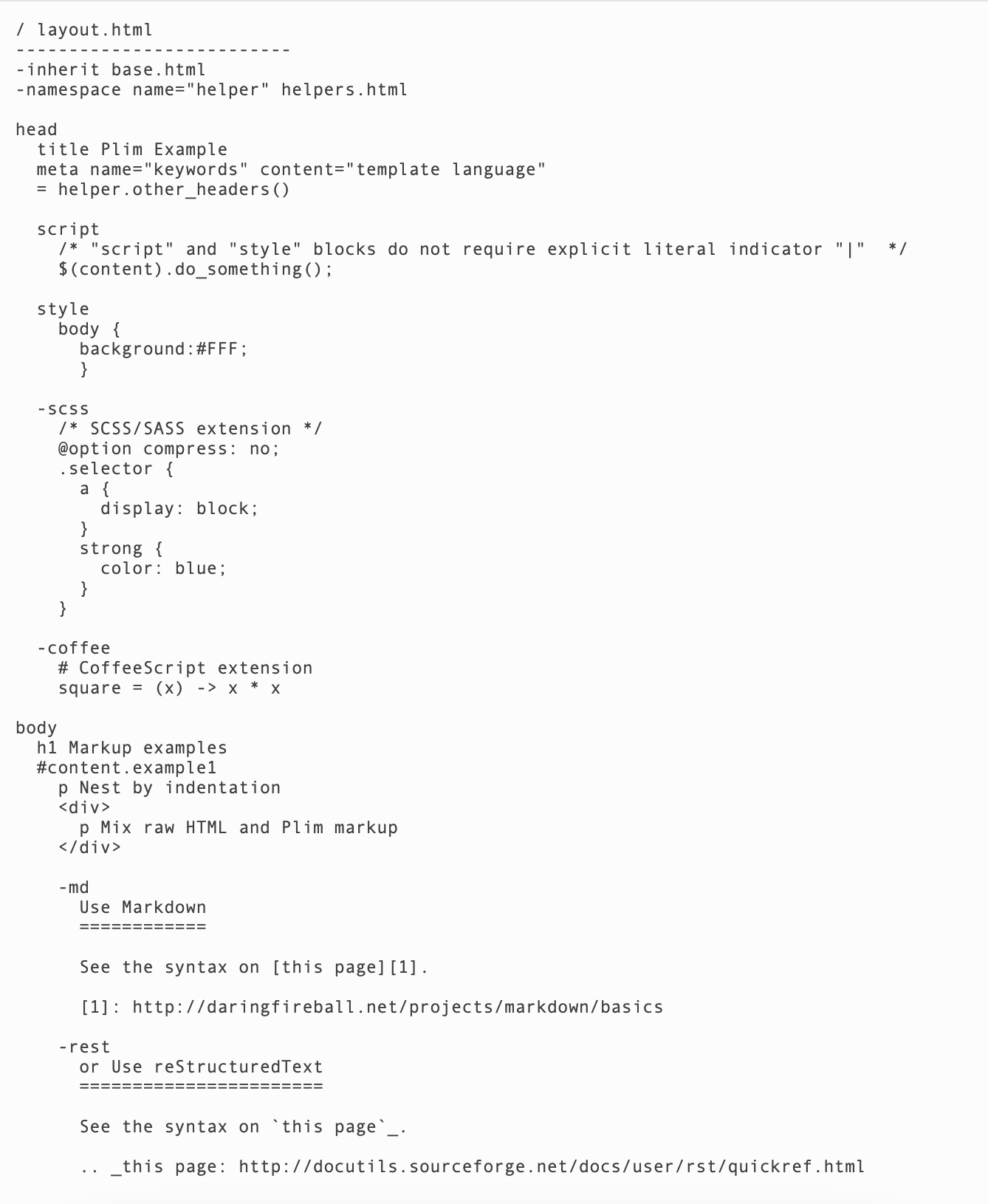
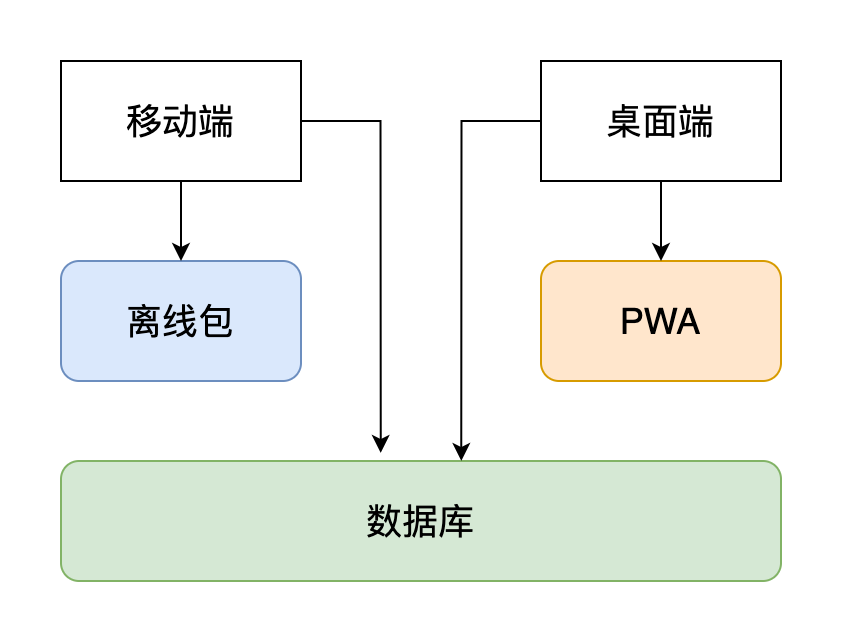
前端三剑客 HTML/CSS/JavaScript。JavaScript 已经飞黄腾达,甚至都不认浏览器这个祖宗了;CSS 痴迷与自己的布局样式、动画和色彩、Houdini 扩展等等,进入了修仙的通道。看来看去只剩 HTML 这个老顽固还在自己的一亩三分地里爬坑,几十年来一点长进都没有。
虽然 web components 让人们看到了重拾 HTML 组件的希望,但随着 Safari 等厂商的不配合,以及深入探究后的继承兼容性问题,最终也没有达成一致。HTML 还是归于一滩死水。但这样的的好处也很明显,像其他领域还在挣破头皮要开发新功能时,HTML 只要能渲染 if/else, for loop,import/include, pipe/filter 就谢天谢地足够日常使用了。
正因如此,其实各家 MVVM 与其说是为了渲染 HTML 而写了个框架,不如说是挂羊头卖狗肉专职搞数据流,只是把随手写的 HTML 模板滥竽充数地塞到了用户面前。而这也造成了各家的模板语言五花八门,根本无法有效互通。
更可恶的是,小程序还有一套模板语言……
这些模板可谓是争奇斗艳,群魔乱舞。但最大的一个问题是,很多模板都在破坏 HTML 自身的图灵完备。几十年后,不要说读懂这段代码,就是运行版本都找不到。
有悲观的博主甚至直接切换到了 web components 来对抗这种不确定性,但这只适合于自娱自乐的自嗨项目,公司级项目肯定不合适。咋办呢?先调研调研用过的模板吧。
In the Ivy model, Angular decorators (@Injectable, etc) are compiled to static properties on the classes (ngInjectableDef). This process takes place without a complete analysis of code, and in most cases with a decorator only. Here, the only exception is @Component, which requires knowledge of the meta-data from the @NgModule which declares the component in order to properly generate the ngComponentDef. The selectors which are applicable during the compilation of a component template are determined by the module that declares that component.
The information needed by Reference Inversion and type-checking is included in the type declaration of the ngComponentDef in the .d.ts. Here, Reference Inversion is the process of determining the list of the components, directives, and pipes on which the decorator(which is getting compiled ) depends, allowing the module to be ignored altogether.
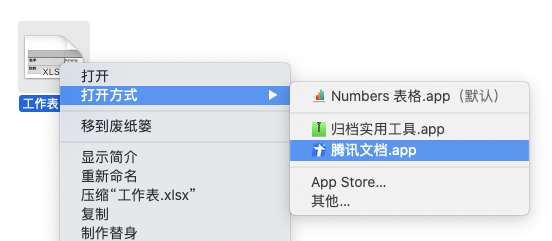
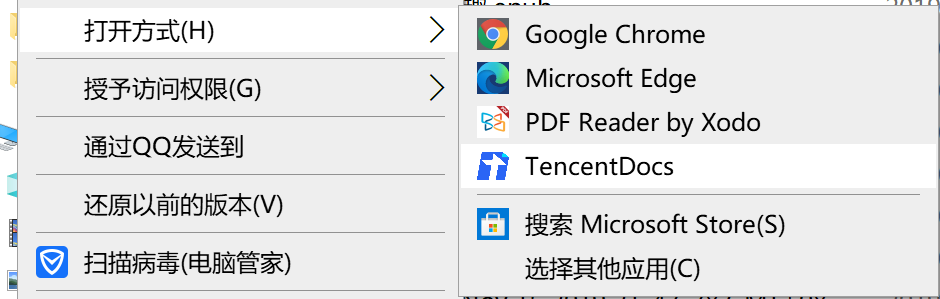
既然都上了客户端,想必用户需要频繁操作的了,这就免不了要和键盘及鼠标事件打交道。常见的输入方式还好,就跟浏览器基本一致,只是遇到过 Mac 上无法通过快捷键复制粘贴的问题。说来都离谱,作为一个文本编辑软件,发布出去时竟然无法使用快捷键 Ctrl + C + Ctrl +V!还好我们很快就发布了版本修复了这个问题。
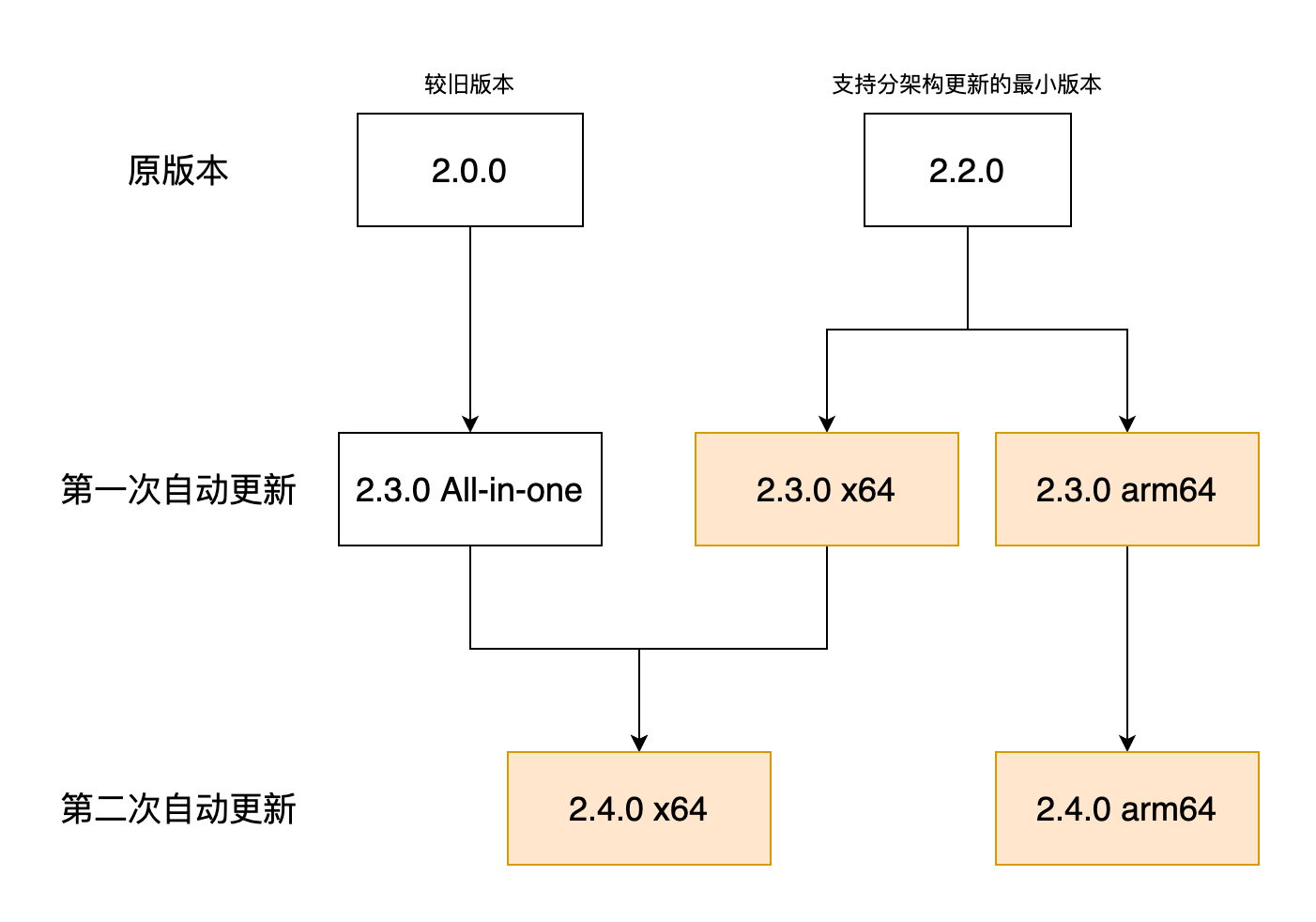
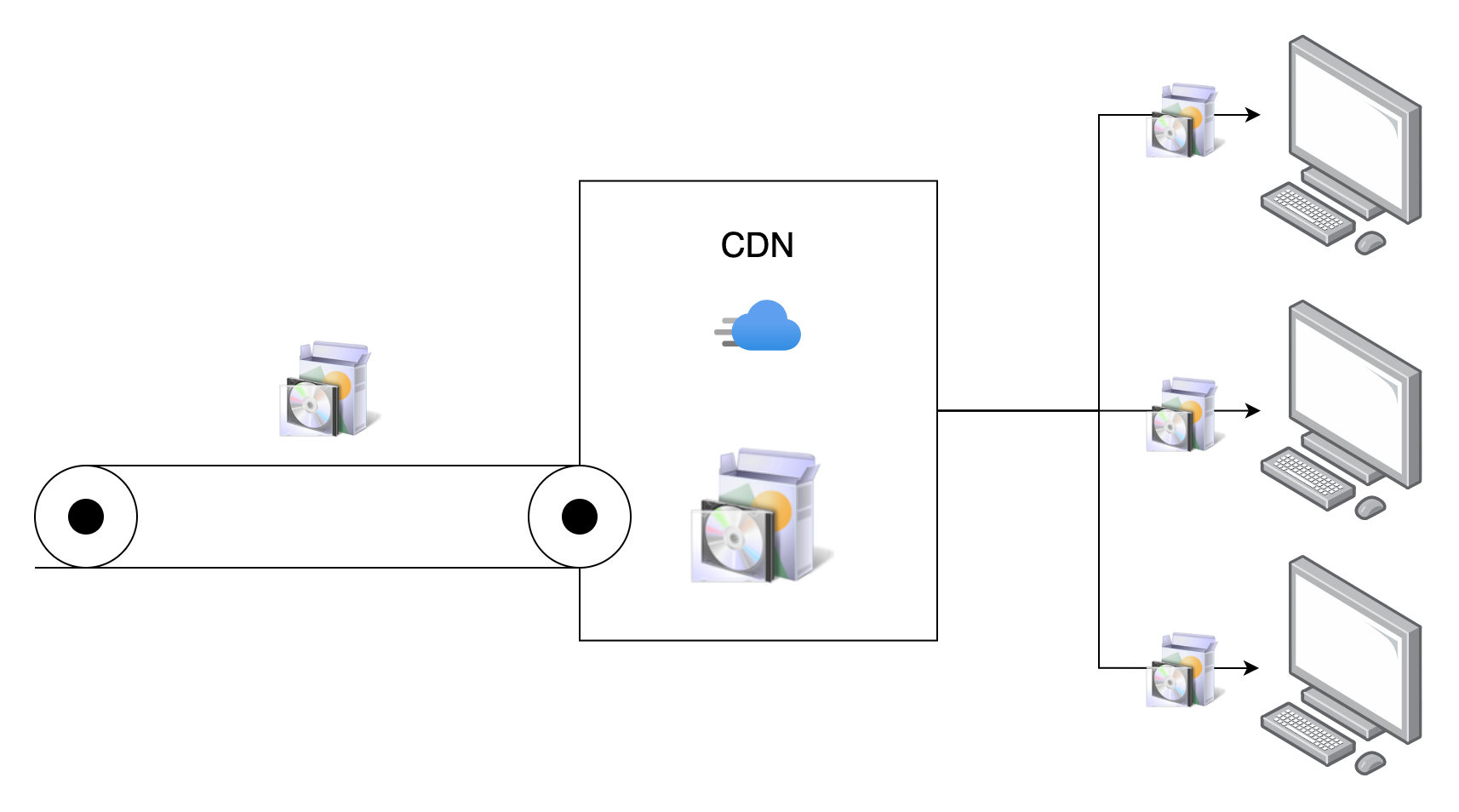
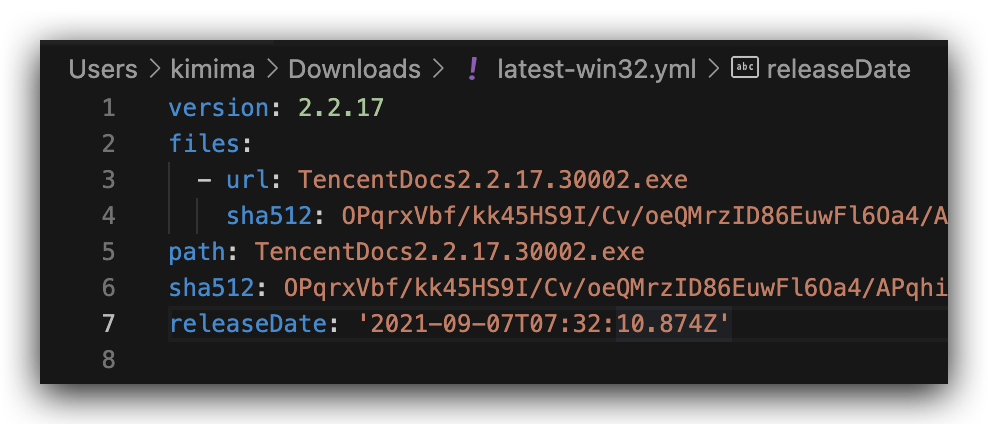
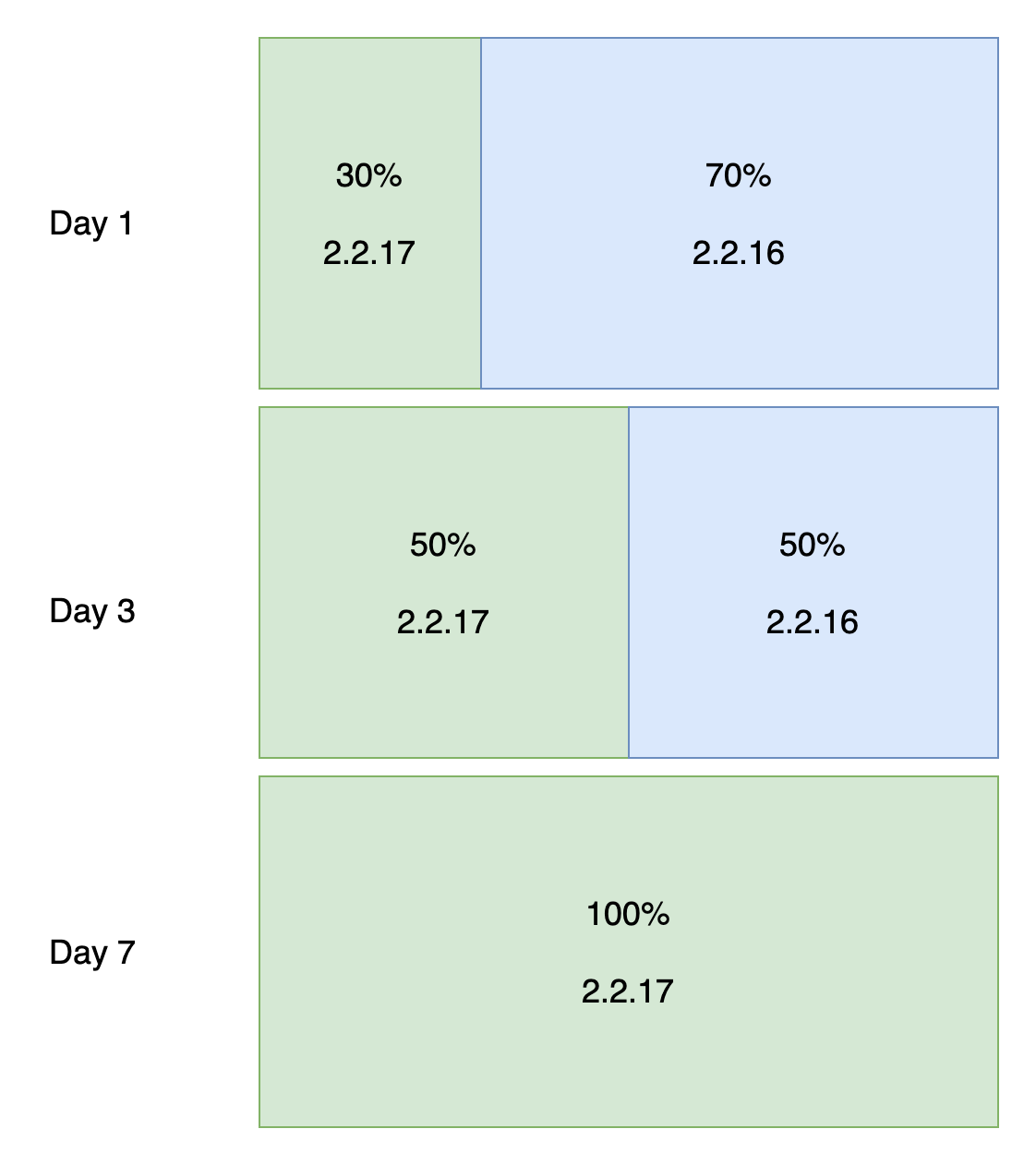
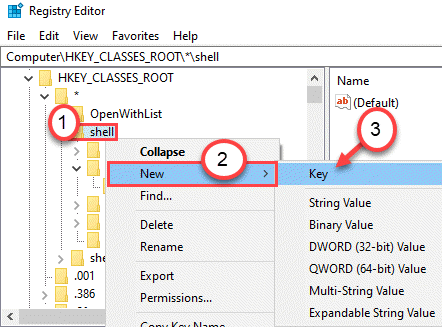
本着用户价值最大化的原则,现在软件大多抛弃了争奇斗艳的安装界面,反正做得越花哨越像流氓软件,Electron 社区标配 electron-builder 打包时提供的默认安装功能就挺好。只不过有时候要考虑旧版本的卸载问题,因为客户端技术更新换代,总有技术断层的阶段,旧版本无法正常自动更新到新版。像 Mac 上软件都进到了全局唯一的软件目录,安装时可以由系统来提示,玩 Linux 的也都是大神,安装不上也会自己手动 remove,但最广大的 Windows 用户迫切需要一键卸载旧版本的功能。我找到了 electron-builder 所依赖的 NSIS 安装器,定制了其安装脚本,在检测到旧版本的卸载程序存在于注册表时,会直接调用这个卸载程序,并等待它成功返回后进行新版本的安装过程。
前面提到过,前端页面往往是单个页面完成单个任务,随用随走,所以其测试也主要针对在线数据。但客户端与之不同的在于有本地数据和系统 API 的差异,这也就决定了如果按照传统的人工测试,其成本是很高的。从效能上讲,如果只是编写的代码虽然可以在不同系统运行,但有多少系统就需要测多少遍,是不够经济的,同时测试人员也不一定完全理解设计意图。答案是得用自动化的测试进行覆盖,这就要求开发人员同时扮演测试者的角色。
但很多时候,用户的问题并不那么简单。看似是 A 除了问题,对比日志后发现 B 也有问题,在 debug B 的过程中发现其依赖于 C。甚至到最后发现这些统统都不是问题所在,用户使用的根本不是你这个软件!这里就陷入了用户给你制造的黑盒。怎么办呢?在现有工具无法保证筛选出正常的反馈时,就得通过作业流程来保证各种类型的 bug 在每个阶段就被精准定位并消灭了。
咦,这么简单吗?是的,JS 本就为了开发效率而生,但事情整到 C++ 层面可就不那么简单了 …… 但天下大事,必作于细,良好的职责划分有利于用不同的工具切准要害,逐个突破,我们接着往下看。
划分 C++ 与 JavaScript 职责
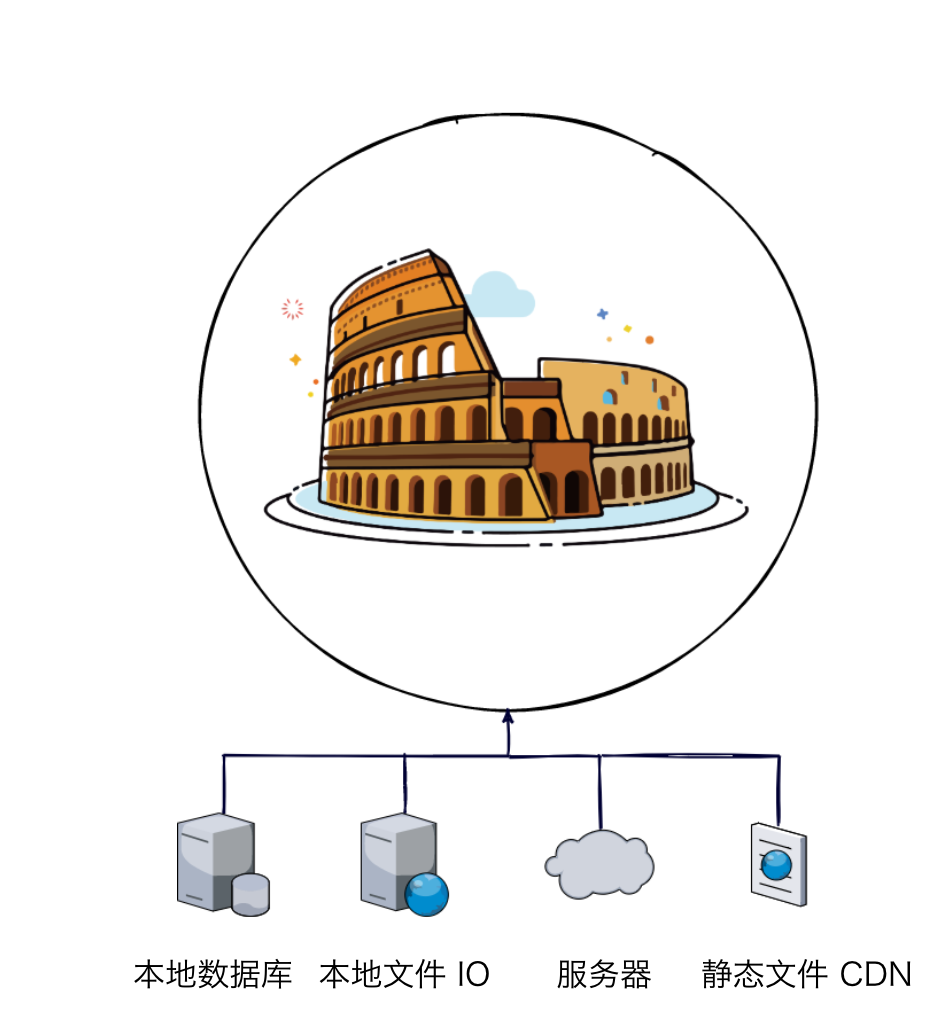
为了 OOP,我们将数据和行为都存放在一起,这会带来一些问题,就是数据该由谁持有?如果 JS 持有数据,将 C++ 作为一个无状态的服务,每次都将数据从 JS 传过来,计算完了传回去,但这样会造成序列化的开销。如果 C++ 持有数据,JS 侧就相当于一个代理,只是把用户请求代理到 C++ 这一边,计算完再转发给用户侧。
实际情况是,一旦涉及到原生调用,C++ 持有的数据很有可能是 JS 处理不了的不可序列化数据,比如二进制的文件,线程 / IO 信息等等,所以还是 C++ 做主导,JS 只做接口比较好。但这样就不可避免地要从 C++ CRUD 一些 JS 对象了,接着往下走。
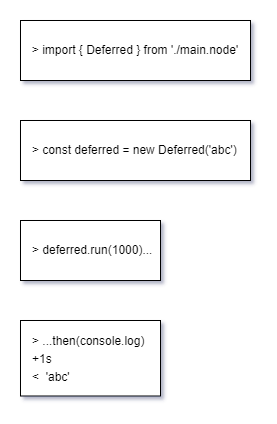
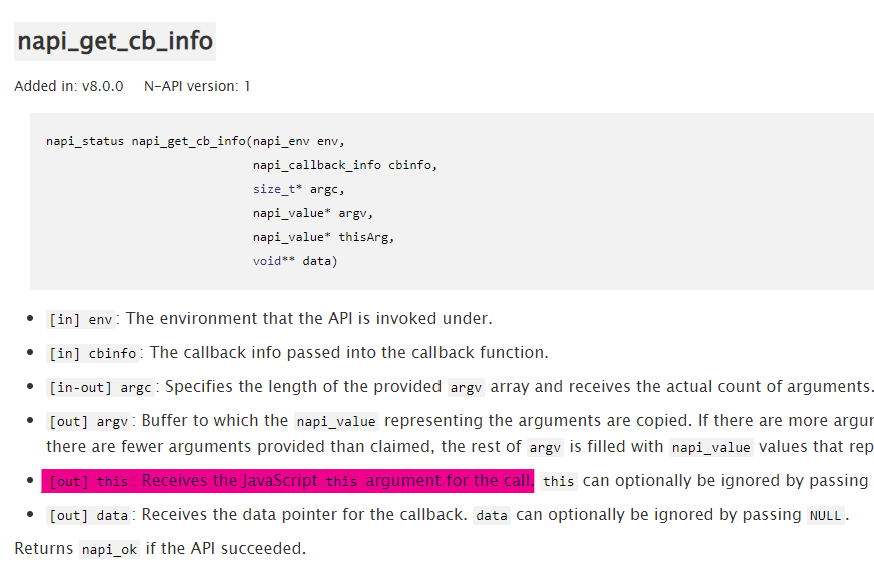
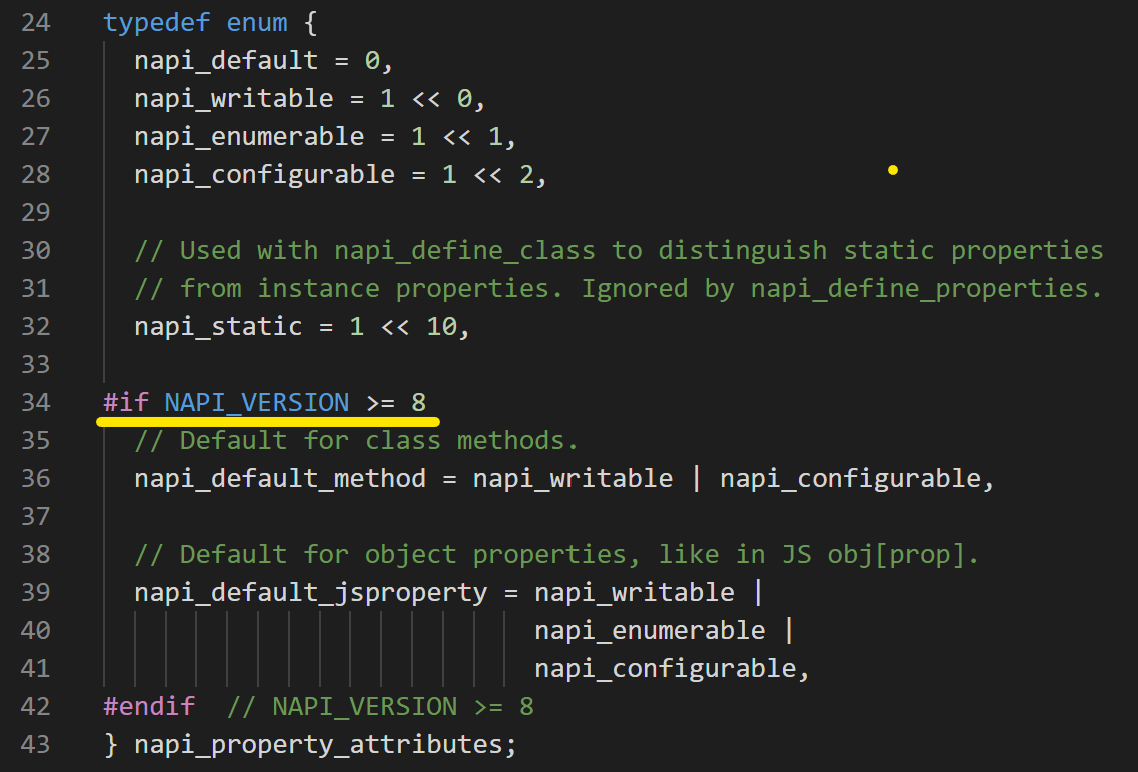
如何解读这些信息呢?有 napi_get_cb_info 这个方法。通过它可以读出包括 this 和各种 ArrayLike 的参数。
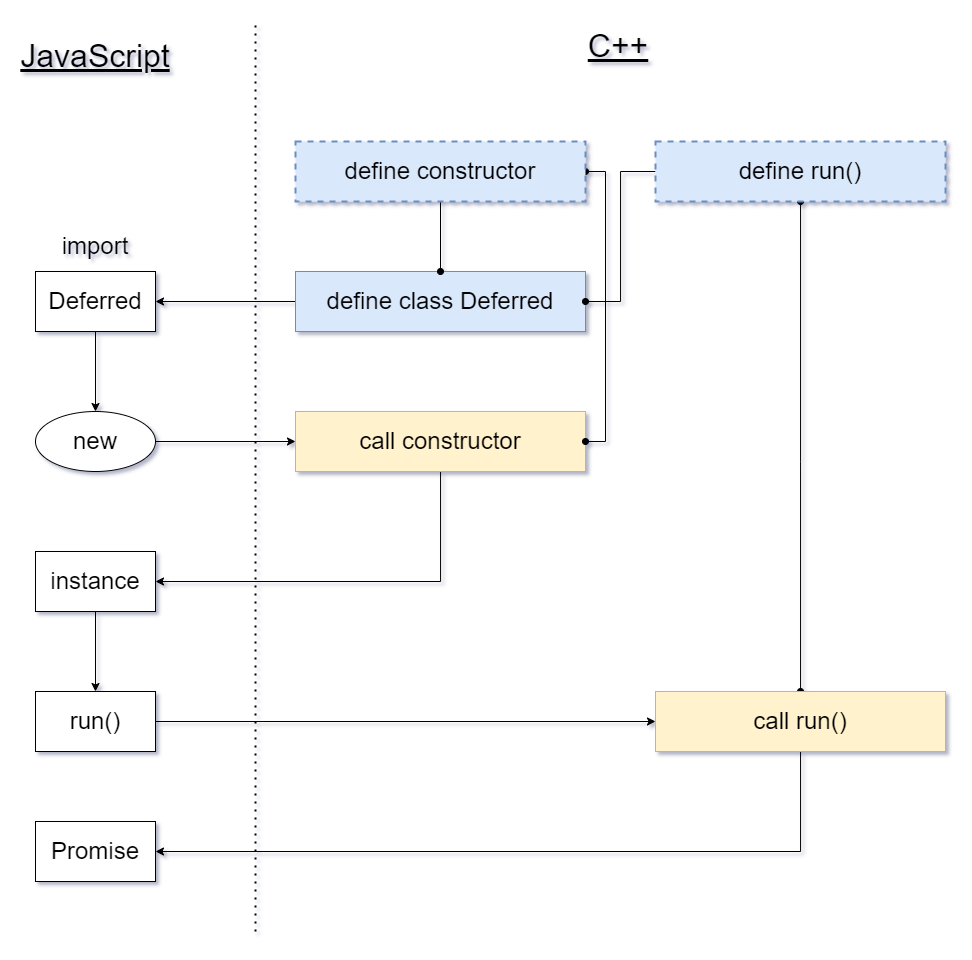
我们在讨论如何创建一个 JS 的 class 啊,这是不是绕太远了?等等,你提到了 this?有的面试题里会考如何手写一个 Object.create,难道这就是那里面默认的 this?你猜对了,这个 this 在通过 Function 创建时,在构造器里是用 v8 的 ObjectTemplate 来实例化一个 instance 的。(PS: 如果 napi_callback 是从 JS 侧调用,那它就是 JS 的那个 this。)
从 JS class 创建对象的话,这个 napi_callback 就是 JS 定义的 constructor,执行完返回 this 就行了,但既然是深度融合 C++ 的功能,我们当然还有别的事要做。
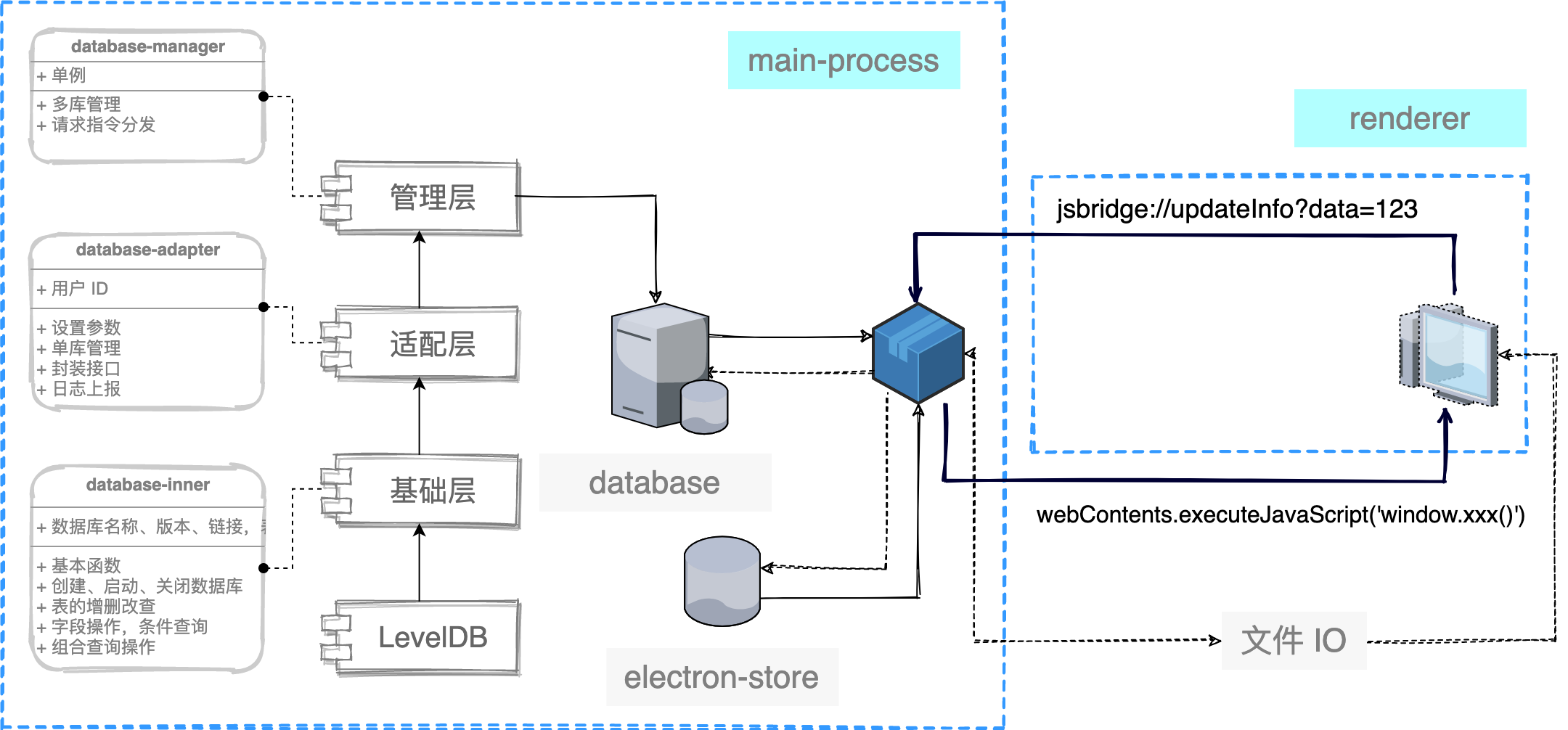
将 C++ 对象封装到 JS instance 上
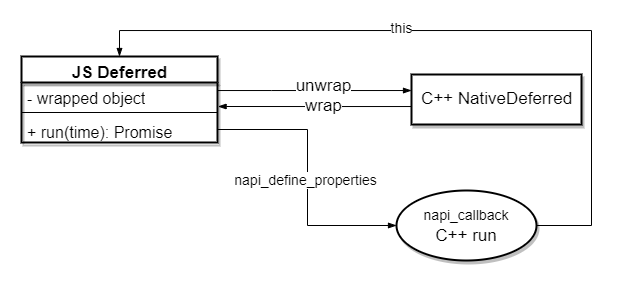
前面声明了一个非常简易的 C++ 对象 NativeDeferred,我们要将它封装到刚创建的 this 上,返回给 JS 侧。为啥要这样做?因为前面提到了,我们要用 C++ 对象持有一些数据和状态,这些不便于在 JS 和 C++ 来回传递的数据需要一个可追溯的容器来承载(即 NativeDeferred),我们可以假设这个容器有两种存储方式:
全局对象,也就是 V8 里的 global,然后生成一个 key 给 JS instance。
挂到 JS instance 上(N-API 支持这种操作)。
很明显第一种方法不仅污染了全局对象,也避免不了 JS instance 需要持有一个值,那还不如直接把 C++ 对象绑到它上面。
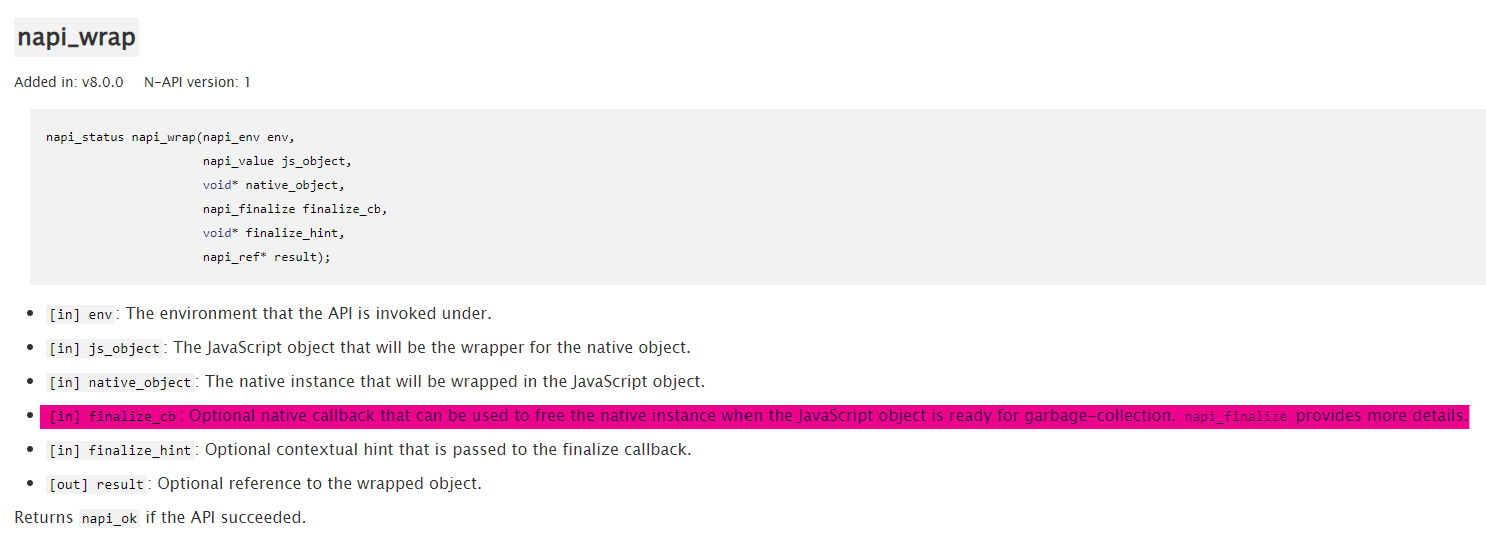
取出 C++ 对象的过程形成了 napi_callback -> JS Deferred(this) -> unwrap C++ NativeDeferred 这样一个线路,需要用到 napi_wrap 和 napi_unwrap 方法。
JavaScript functions can normally only be called from a native addon’s main thread. If an addon creates additional threads, then Node-API functions that require a napi_env, napi_value, or napi_ref must not be called from those threads.
When an addon has additional threads and JavaScript functions need to be invoked based on the processing completed by those threads, those threads must communicate with the addon’s main thread so that the main thread can invoke the JavaScript function on their behalf. The thread-safe function APIs provide an easy way to do this.
With prebuildify, all prebuilt binaries are shipped inside the package that is published to npm, which means there’s no need for a separate download step like you find in prebuild. The irony of this approach is that it is faster to download all prebuilt binaries for every platform when they are bundled than it is to download a single prebuilt binary as an install script.
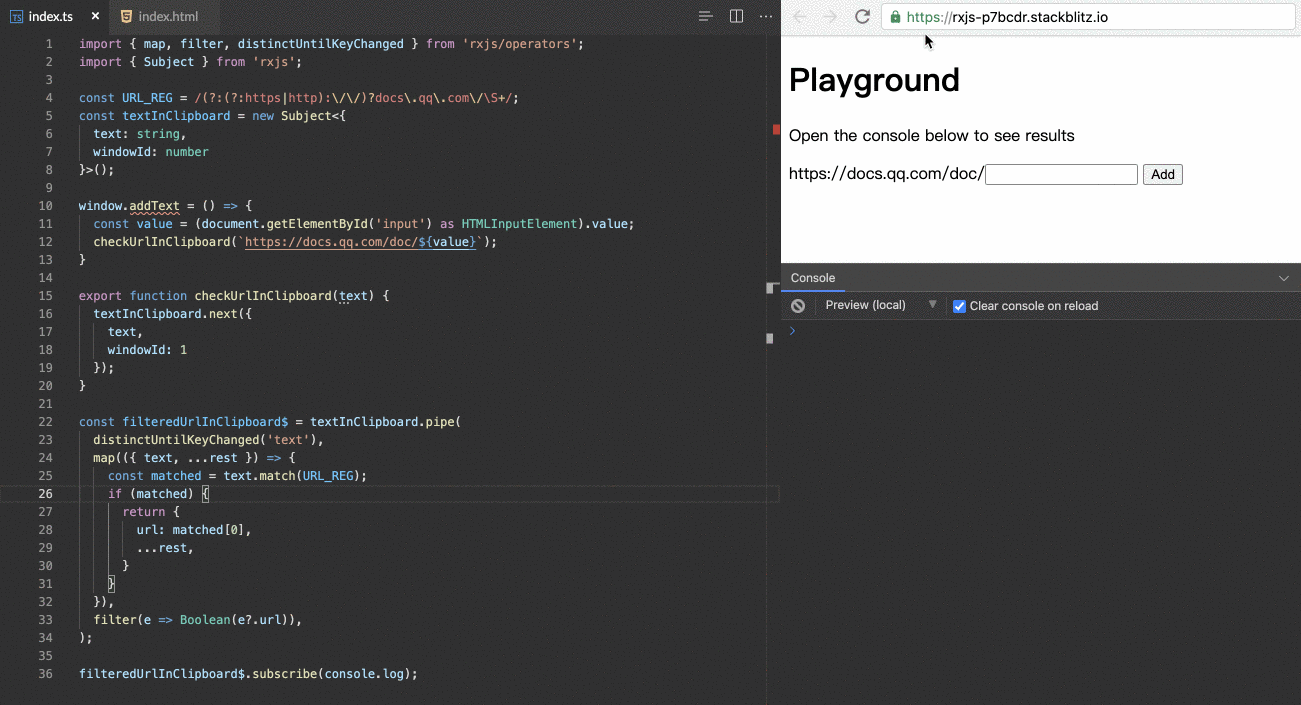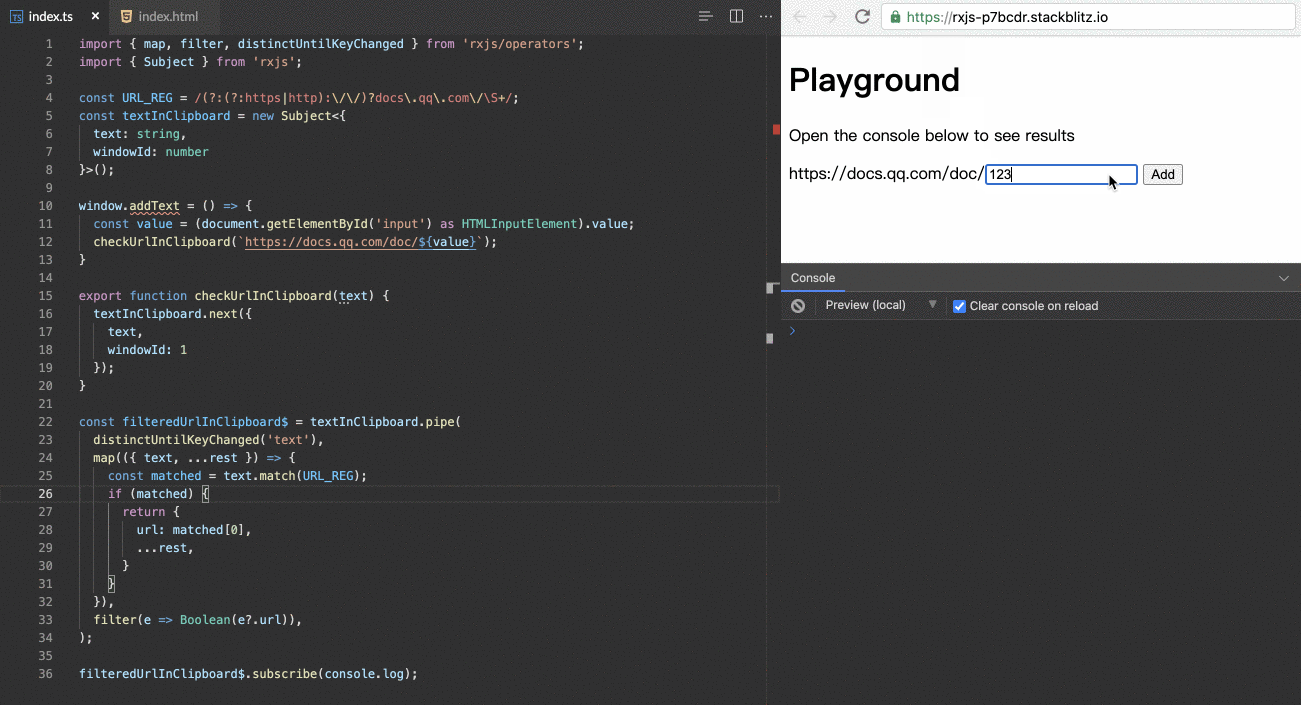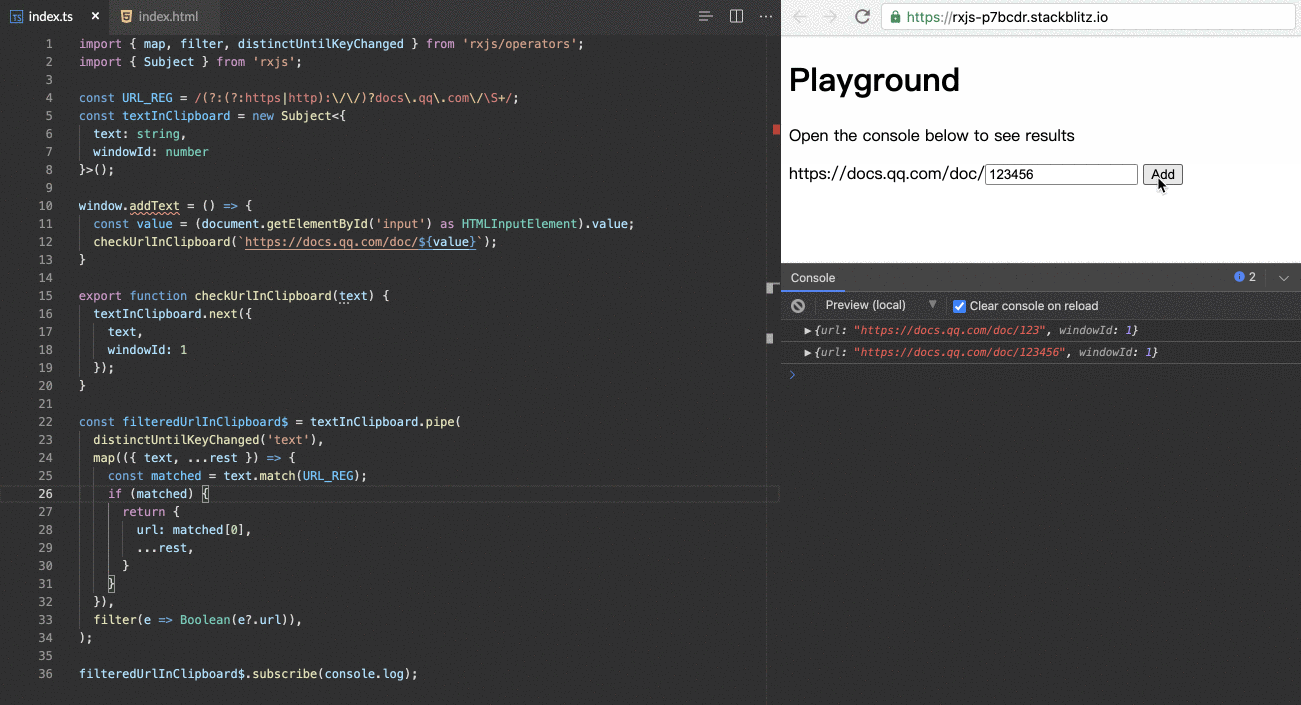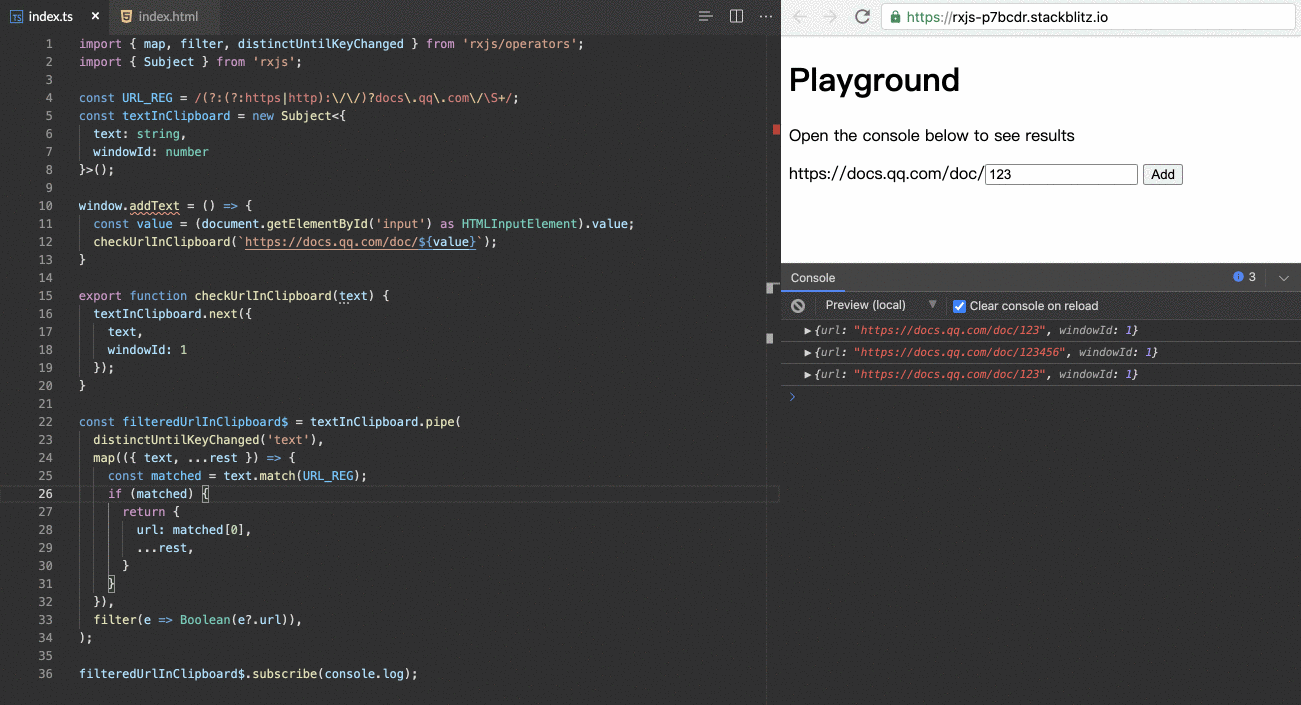
RxJS is a library for composing asynchronous and event-based programs by using observable sequences. It provides one core type, the Observable, satellite types (Observer, Schedulers, Subjects) and operators inspired by Array#extras (map, filter, reduce, every, etc) to allow handling asynchronous events as collections.
事实上,这也是我们一开始进行技术选型和开发规划时所考虑的问题,因为选择了使用 JavaScript 及 Web 技术开发客户端,就注定了与 web 开发息息相关,包括迭代周期和开发顺序等方面,web 端腾讯文档的发布周期是一周两次发布,在一个月时间内差不多可以交付一系列完整的 API,这样可以做到桌面端与 web 端并行开发,最终整合成一个整体。如果等到半年时间才交付了桌面端,这时 web 端应用的 API 和 JSBridge 等接口规范都可能随之发生改变,容易造成返工甚至二次开发。
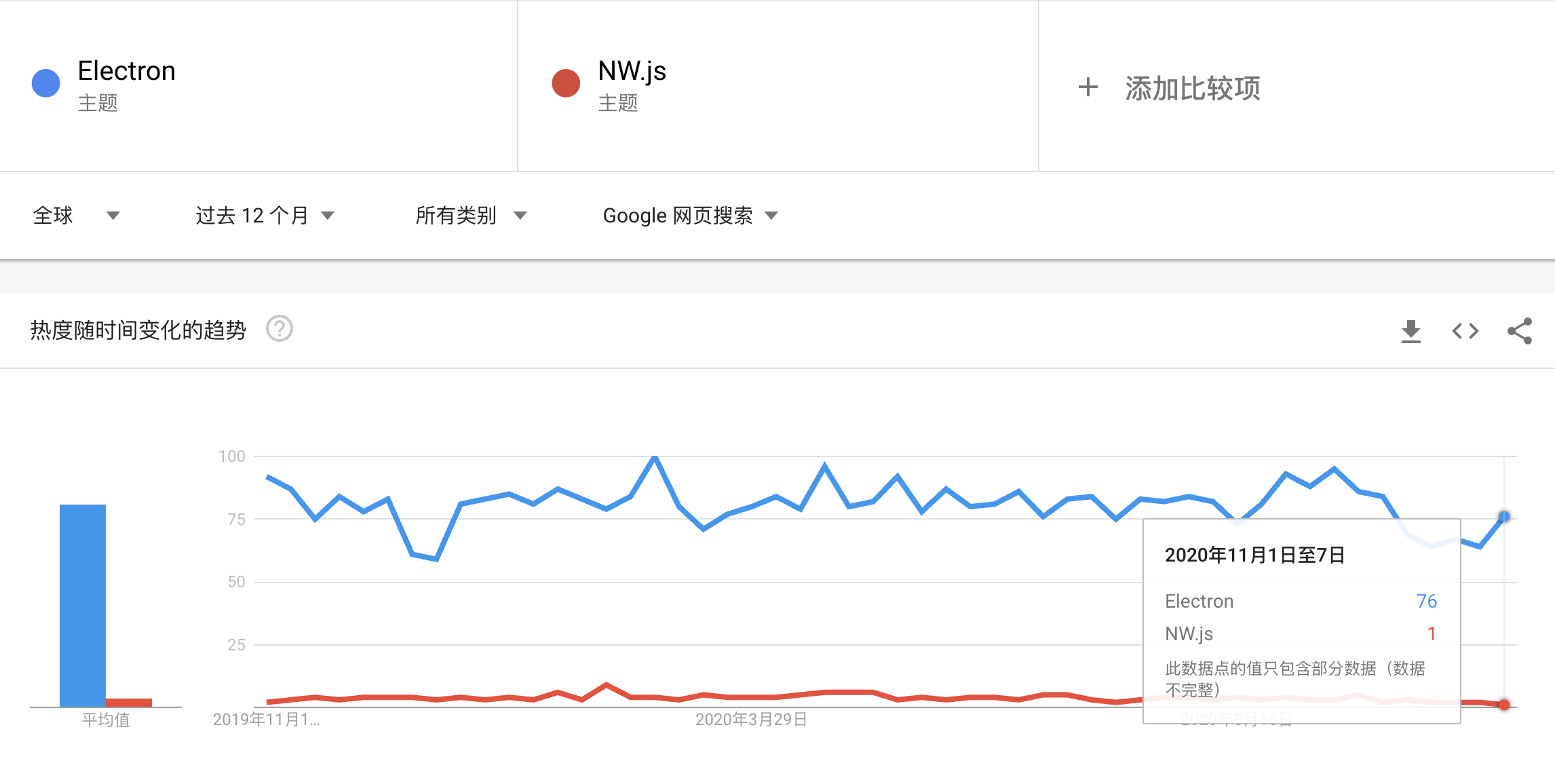
首先是总体的开发框架选择,结果是没有疑问的,我们选择了 Electron,实际上 NW.js 前身 node-webkit 和 Electron 的开发团队具有继承关系,而 NW.js 的特点是以 html 作为启动文件,在窗口里直接调用 Node.js,但我们知道能力越大责任越大,同时风险系数也越高。Electron 的主进程是跑在 Node.js 环境下的,可以无缝使用 Node.js 能力,而单独的窗口,即渲染进程,需要显式地打开开关才能使用,这样就一定程度上降低窗口中的页面滥用 Node.js 能力对系统造成危害或者频繁调用 Node.js 能力对性能产生影响的可能性。在插件、第三方包、社区生态和搜索热度上, Electron 都完胜于 NW.js,所以我们就放心地使用 Electron 进行开发吧。
社区优质实践
既然选定了 Electron 作为开发框架,先来看一看业界基于 Electron 的优质实践,首当其冲的是宇宙第一 IDE 的 Visual Studio 的 …… 挂名弟弟 …… Visual Studio Code,同样是微软出品,现已成为 web 开发事实上的标准 IDE。
然后是 Github 出品的 Atom 编辑器,这里插一句题外话,Electron 原名”Atom Shell”,后来随着框架的进一步抽离和沉淀,改名为”Electron”,这点非常符合国外技术圈觉得”工具不好用就发明一个趁手的工具”的思路。以及同样是 GitHub 出品的 GitHub Desktop 客户端,其他知名的基于 Electron 开发的桌面软件还有协作办公软件 Slack、 IM 即时通讯软件 WhatsApp 和 知识协作软件 Notion 等。
构建工具
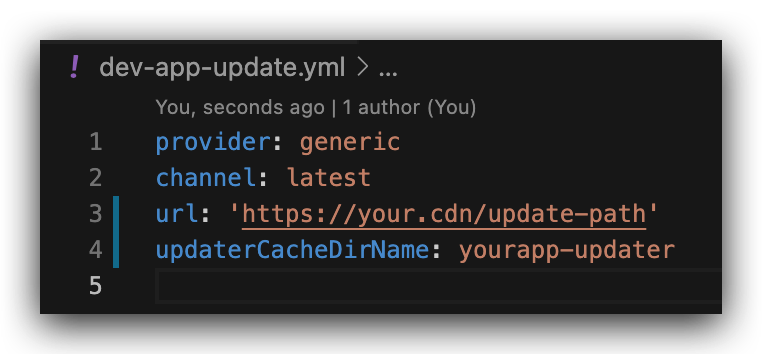
我们做桌面端应用与 web 端应用差异最大的在于分发方式不同,web 端应用打开页面浏览即为分发成功,而桌面端应用则必须要下载到本地安装后使用,所以提升下载与安装体验对用户增长率提升至关重要。而提到安装包,就不得不提一下 electron-builder,它不仅做到了轻配置快速构建,也带给了桌面端应用非常多的额外能力,例如系统级别的文件关联,自动签名认证功能,制品管理和安装流程定制等,这些都与后面讲到的工程化建设和跨端体验一致性密切相关。通过一套配置,即可构建出包括自动更新、App Store 发布包在内的多个制品。
单测框架
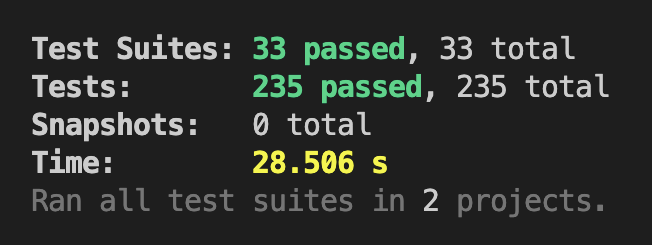
如果说安装包是团队给用户的交付物的话,代码就是开发给团队的交付物。好的代码应该是可测试、可维护和承上启下的,要做到这些的最佳实践形式就是编写测试。而多种多样的测试里最方便快速的就是单元测试了,针对 Electron 的测试方式与常见 web 端测试不同,也可以认为是分别在 JSDOM 和 Node.js 两种环境下进行测试。经过调研,我们引入了 @jest-runner/electron 作为我们的单测框架,它的优势是一套配置,根据文件目录分发到两种执行环境下运行,也就是前面提到的主进程和渲染进程。并且具有代码无侵入,配置简单,速度飞快等特点。
在前一篇文章中笔者主要介绍了使用 Electron 进行开发过程中打包、构建、自动升级与文件关联相关的内容,细心的读者可能已经发现其中并没有提到与界面相关的话题。时隔一个月,中间又经历了一些需求迭代开发和代码维护,这篇文章将会尽可能详细地介绍 Electron 跨端开发中用户界面部分与平台及系统差异相关的注意点,并探索建立支持自定义多范式的窗口管理方式。
窗口开发基础
我住长江头,君住长江尾,日日思君不见君,共饮长江水。 —— 李之仪
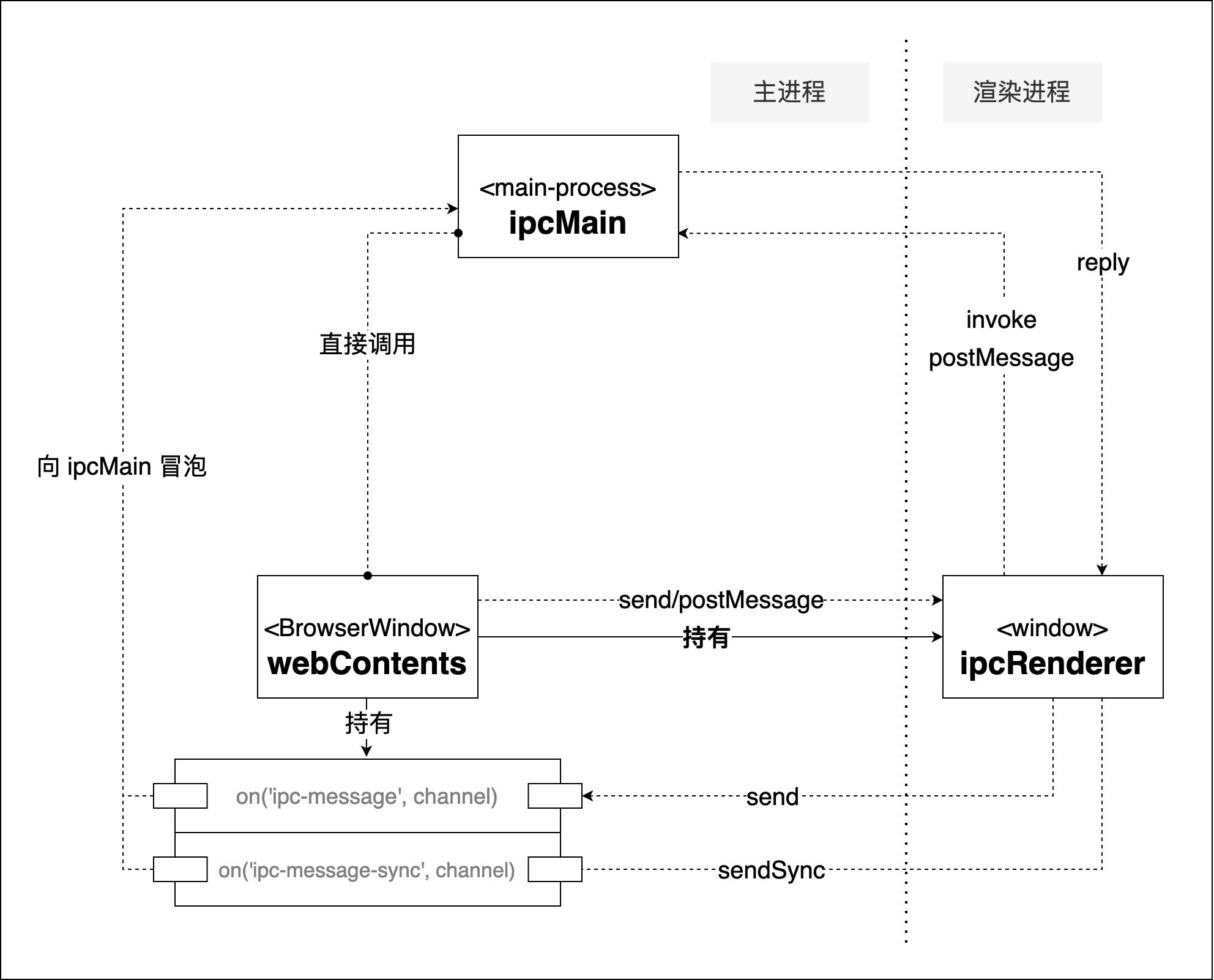
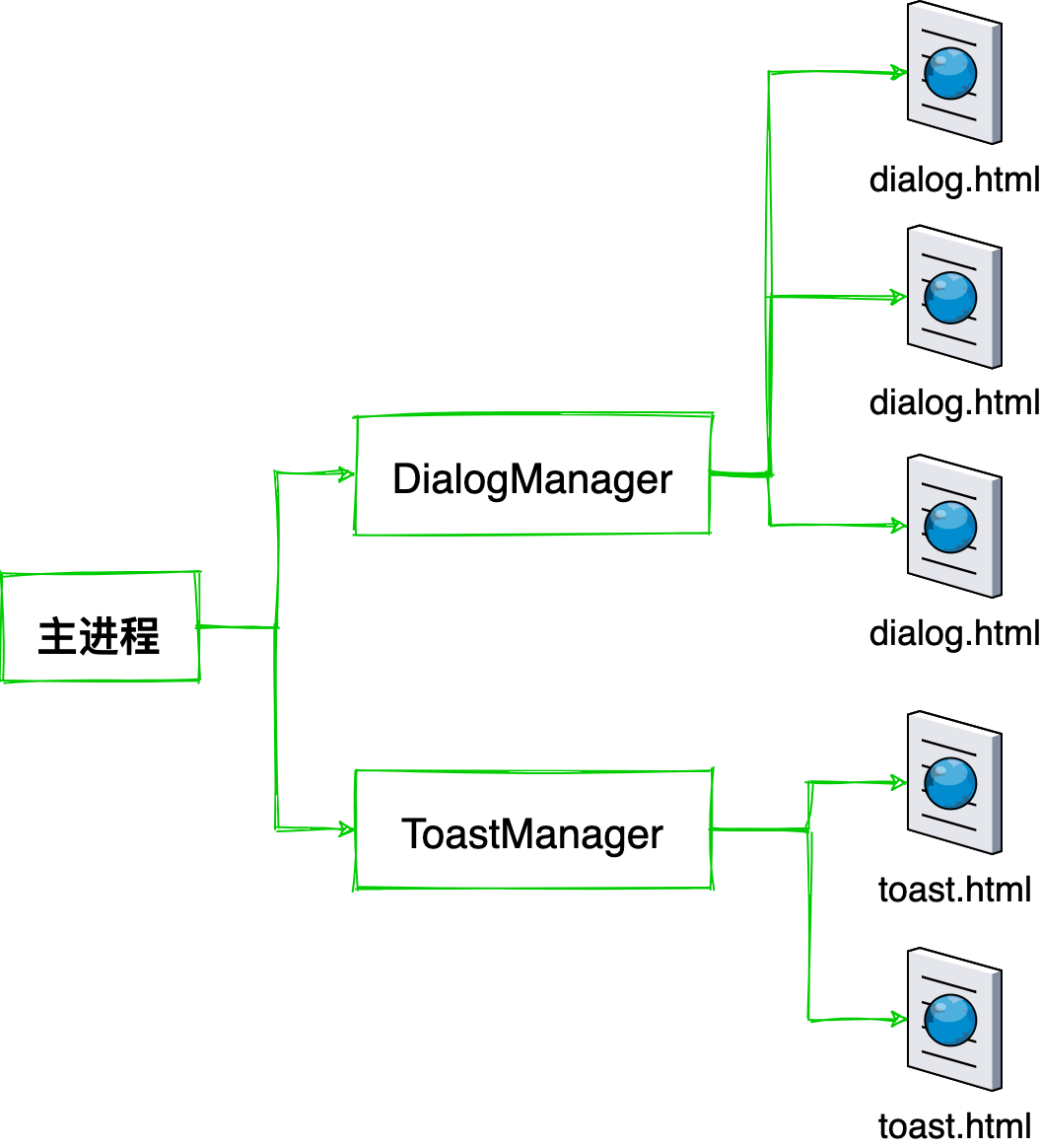
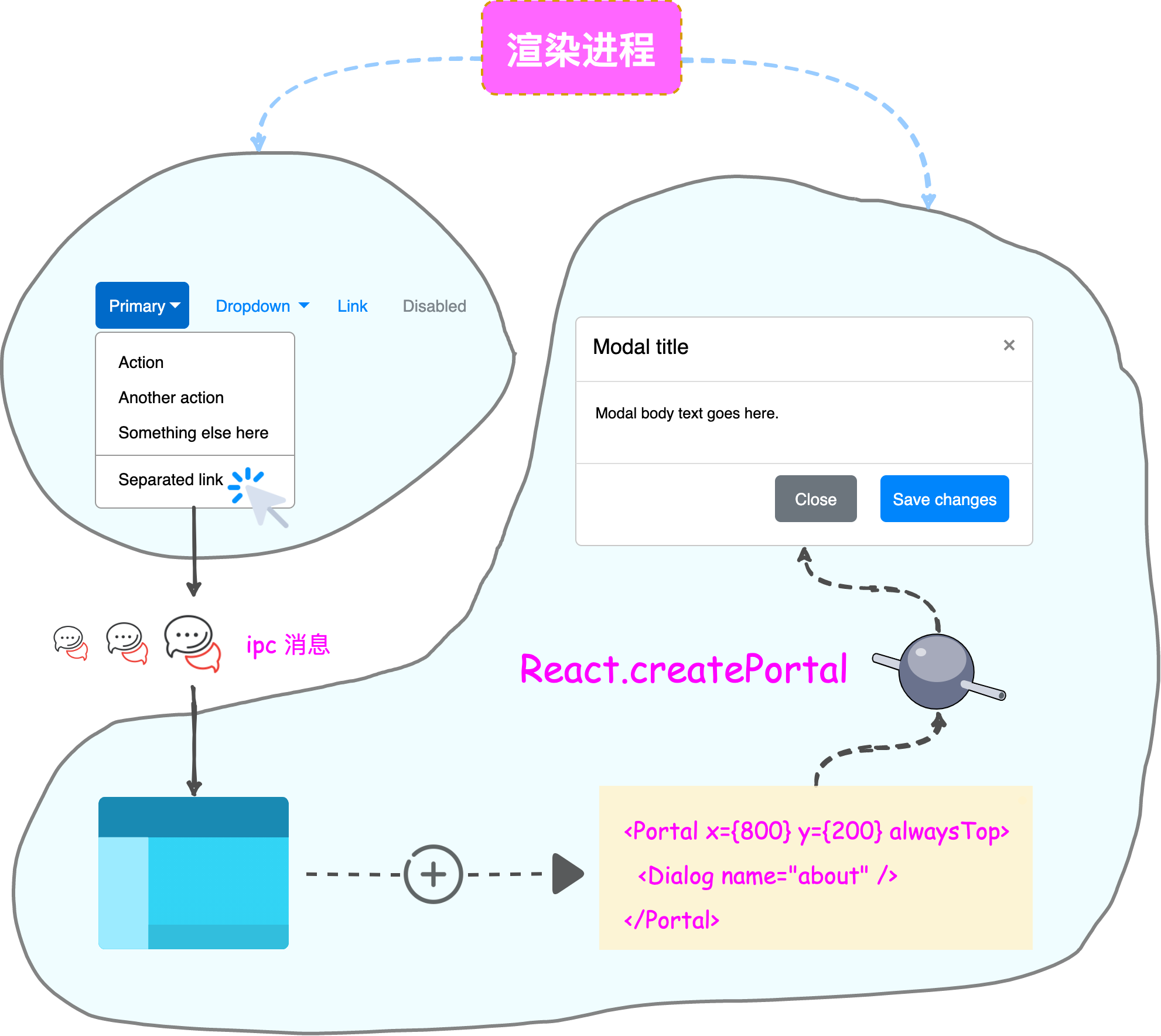
通信方式
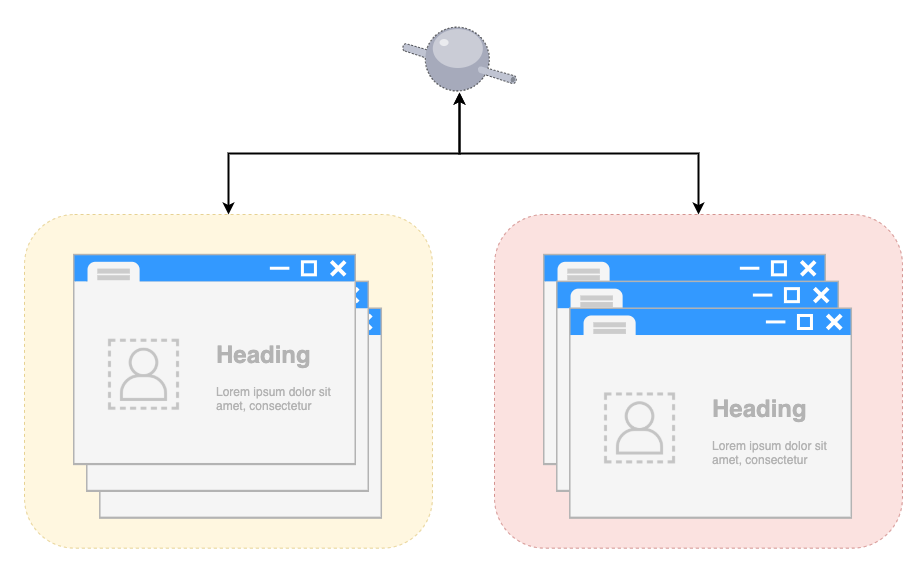
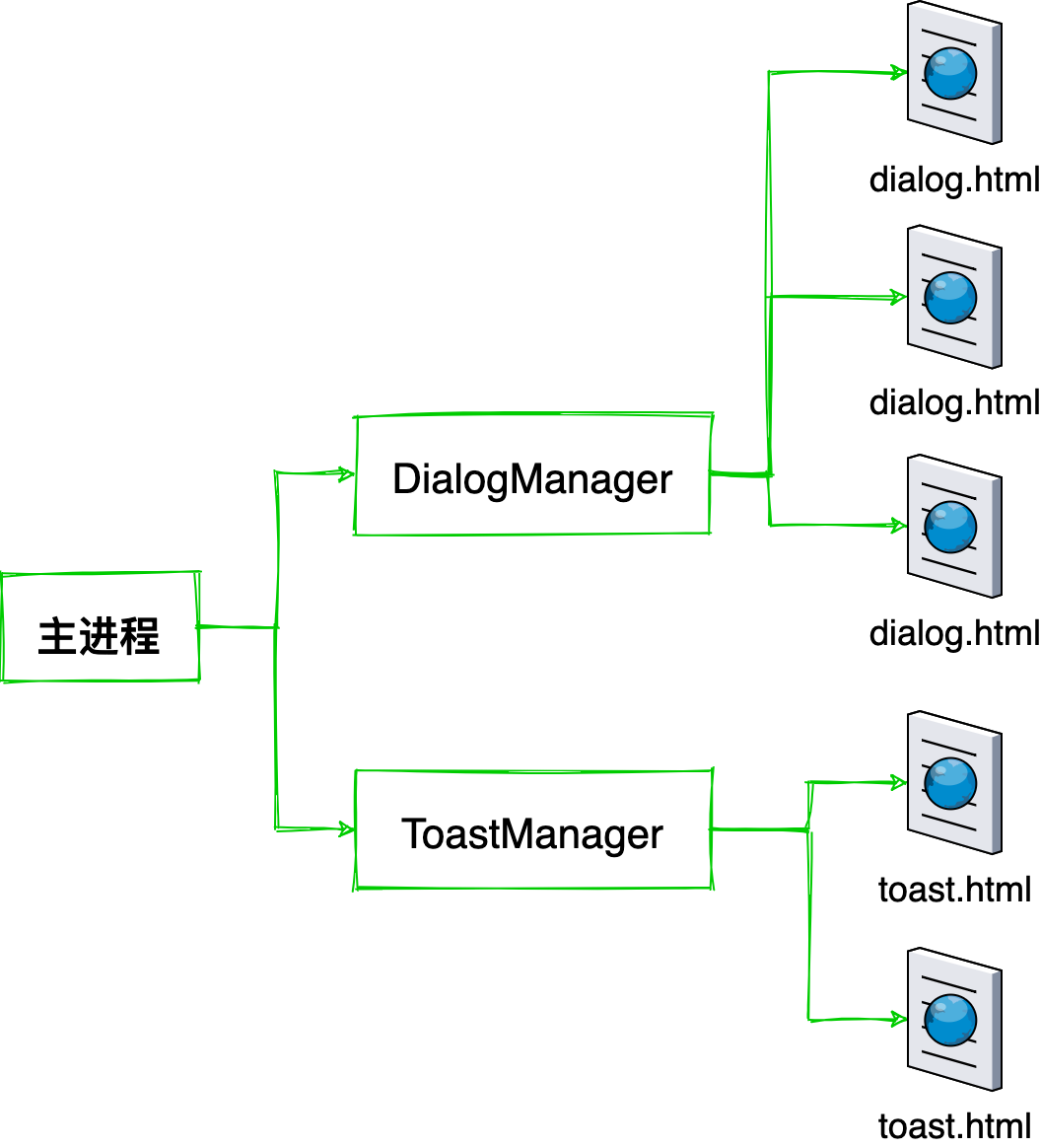
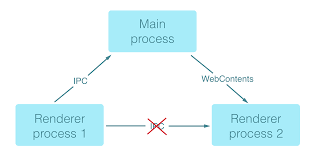
我们知道所有 Electron 自定义的窗口界面都是跑在渲染进程里的,而讲到渲染进程则不得不提到主进程。《卜算子》这首小令非常形象地道出了同一个应用里不同渲染进程和主进程之间的关系:一个应用实例只有一个主进程,而会有多个渲染进程。渲染进程之间是无法直接通信的,他们必须要通过主进程这条”长江”来通讯。
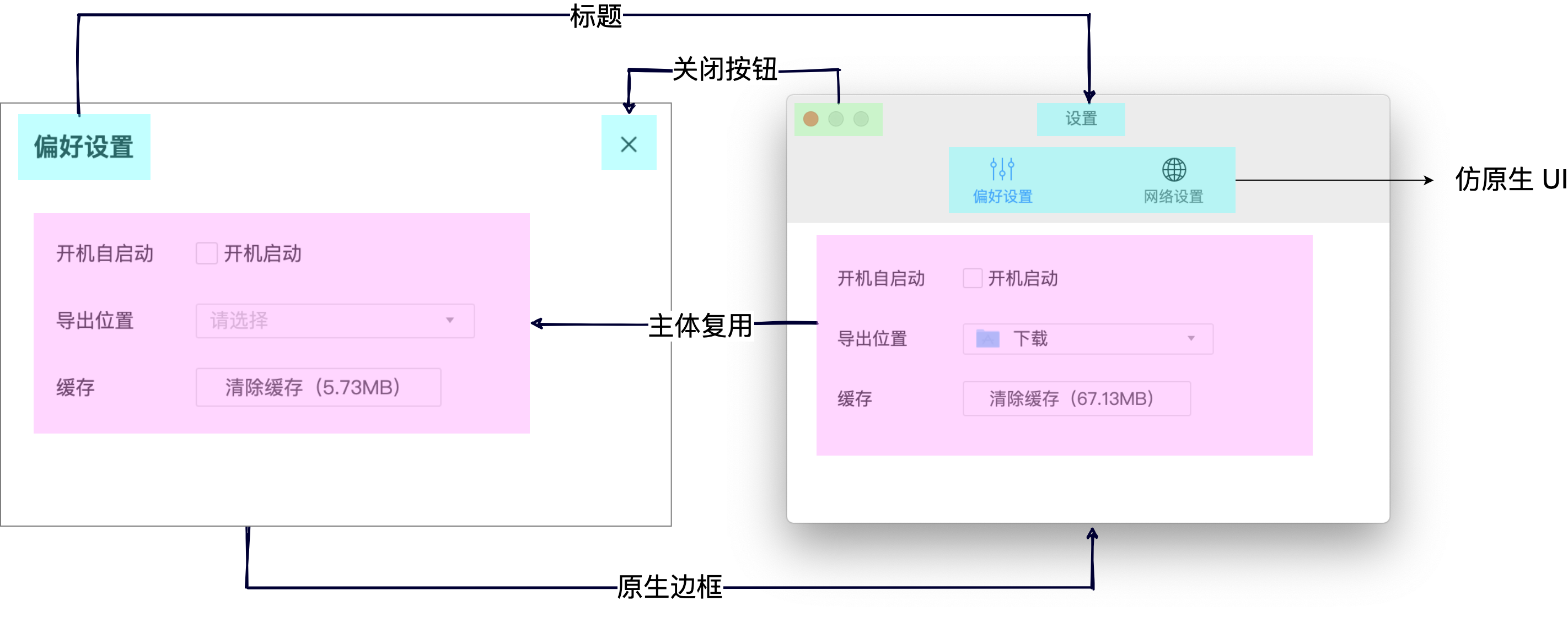
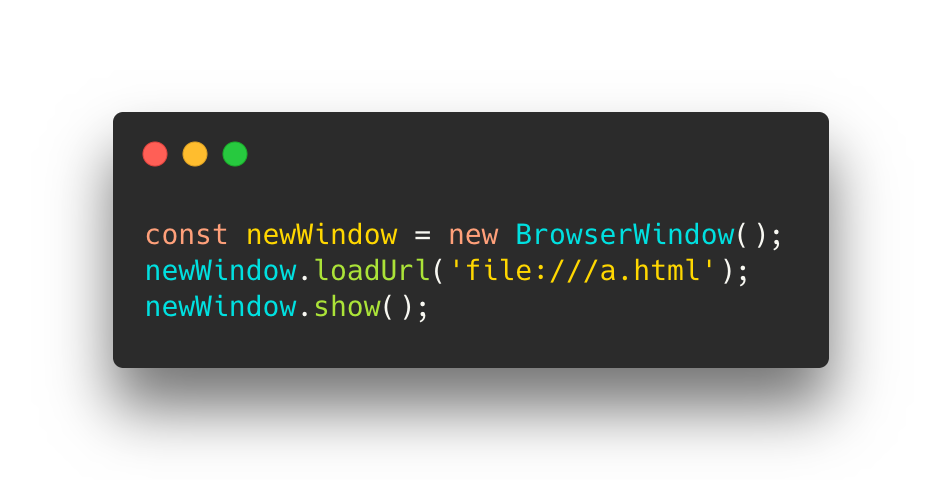
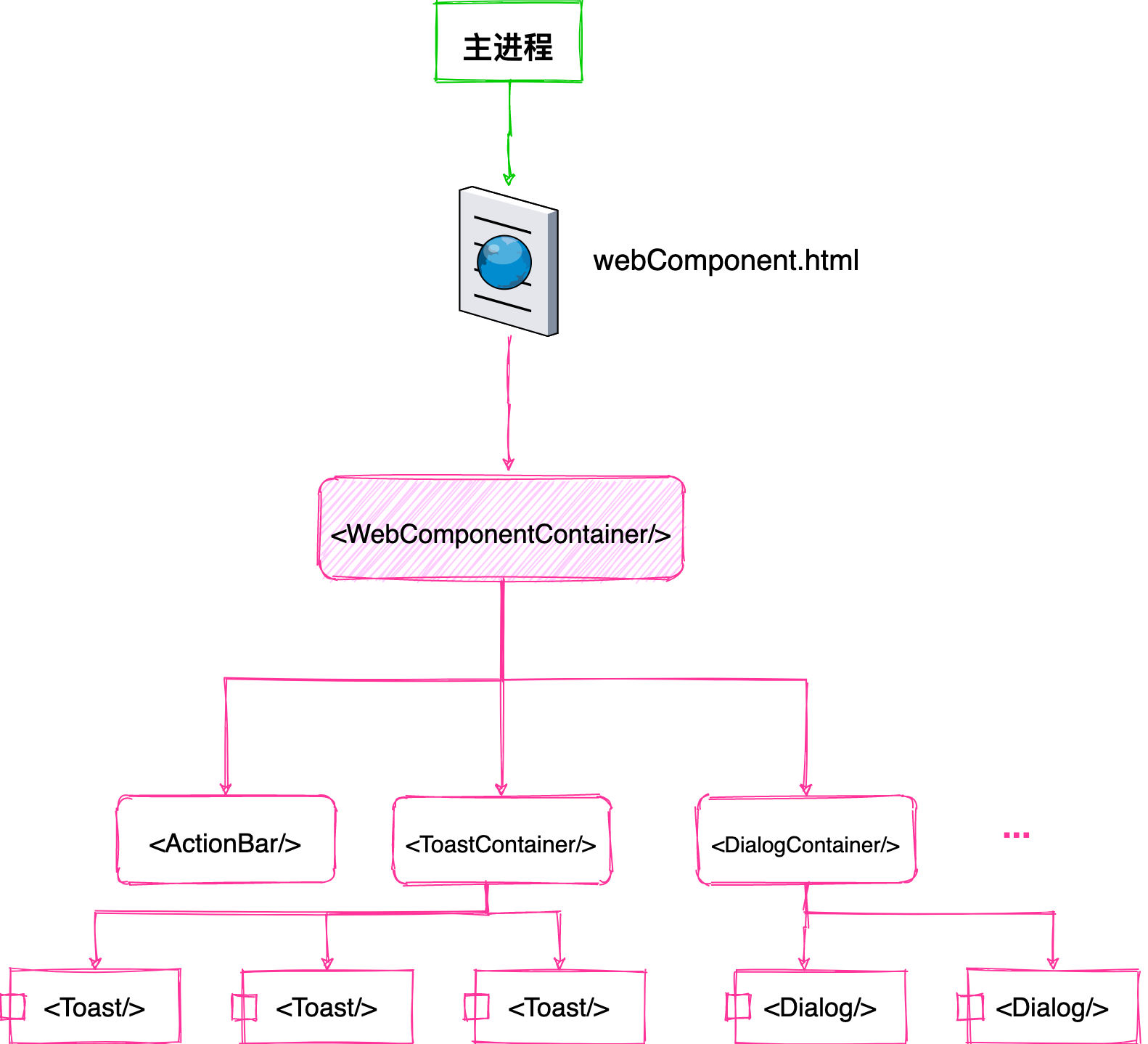
但这时有一个问题,窗口内加载的仍是 web 页面,本质是一个个 HTML 文件,而我们知道 HTML 并不能互相嵌套 …… 虽然曾有过 HTML Imports,但其在 MDN docs 上已被标记为过时且不建议使用,我们仍然需要一个组合 HTML 的机制否则我们的页面文件随着需求的增加就会变成一个冗长的 entry 列表。
代码风格
“Imperative programming is like how you do something, and declarative programming is more like what you do.”
如上图,如果 a - b < 0,则将 a 放在 b 的左边,如果 a - b === 0 则保留两者位置不变,如果 a - b > 0,则将 a 放到 b 的右边,简单朴素地说明了排序的基本原则,而具体排序是用什么方式,时间复杂度和空间复杂度都不要用户去关注(如果想要进一步了解 Array.sort 的实现可参见这篇 StackOverflow 的回答)。
exportfunctioncopyStyles(sourceDoc: Document, targetDoc: Document) { const documentFragment = sourceDoc.createDocumentFragment(); Array.from(sourceDoc.styleSheets).forEach((styleSheet) => { // for <style> elements if (styleSheet.cssRules) { const newStyleEl = sourceDoc.createElement('style');
Array.from(styleSheet.cssRules).forEach((cssRule) => { // write the text of each rule into the body of the style element newStyleEl.appendChild(sourceDoc.createTextNode(cssRule.cssText)); });
documentFragment.appendChild(newStyleEl); } elseif (styleSheet.href) { // for <link> elements loading CSS from a URL const newLinkEl = sourceDoc.createElement('link');
<scriptcontext="module"lang="ts"> functioncopyStyles(sourceDoc: Document, targetDoc: Document) { Array.from(sourceDoc.styleSheets).forEach(styleSheet => { if (styleSheet.cssRules) { // for <style> elements const newStyleEl = sourceDoc.createElement('style'); Array.from(styleSheet.cssRules).forEach(cssRule => { // write the text of each rule into the body of the style element newStyleEl.appendChild(sourceDoc.createTextNode(cssRule.cssText)); }); targetDoc.head.appendChild(newStyleEl); } elseif (styleSheet.href) { // for <link> elements loading CSS from a URL const newLinkEl = sourceDoc.createElement('link'); newLinkEl.rel = 'stylesheet'; newLinkEl.href = styleSheet.href; targetDoc.head.appendChild(newLinkEl); } }); } </script>
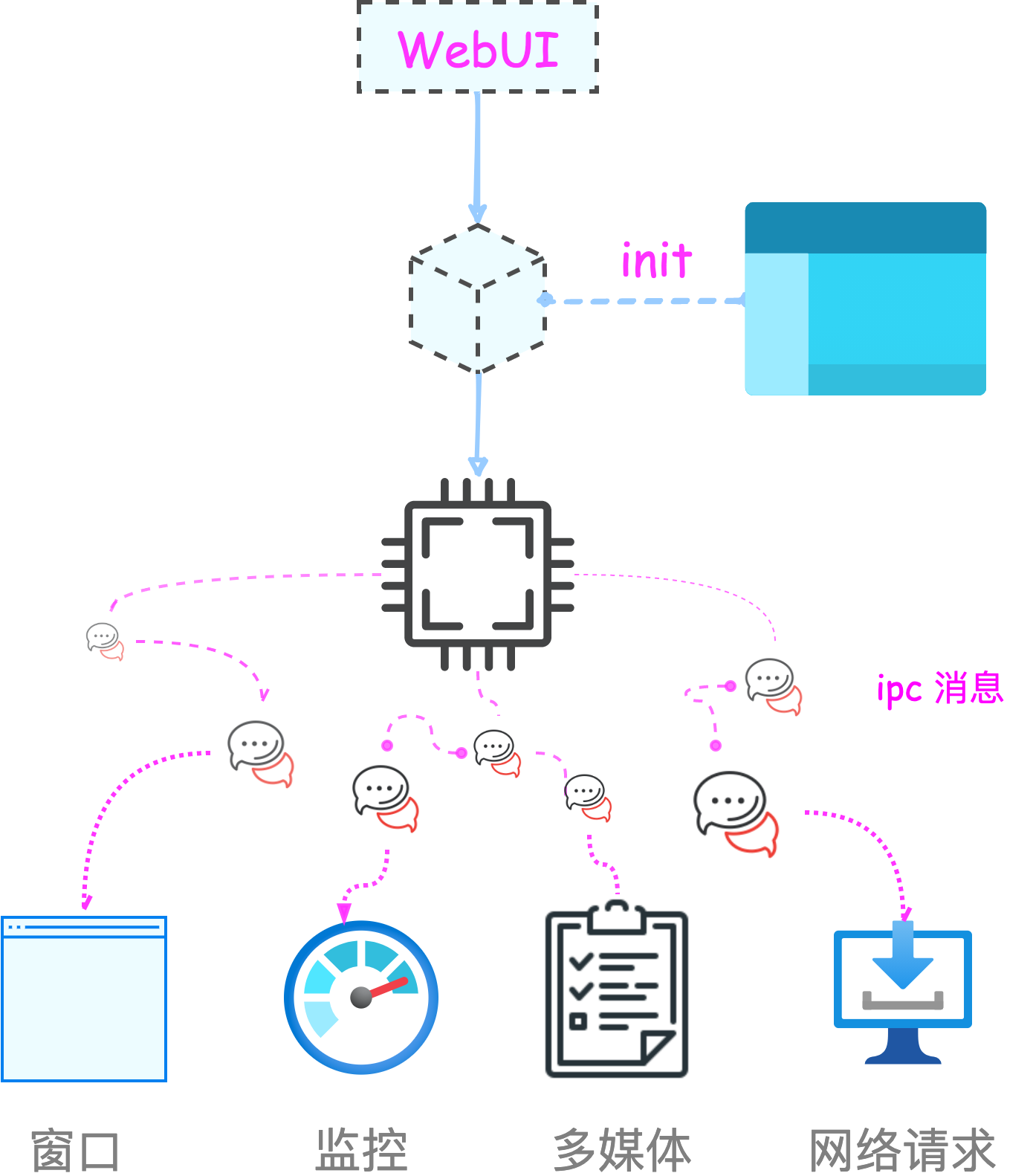
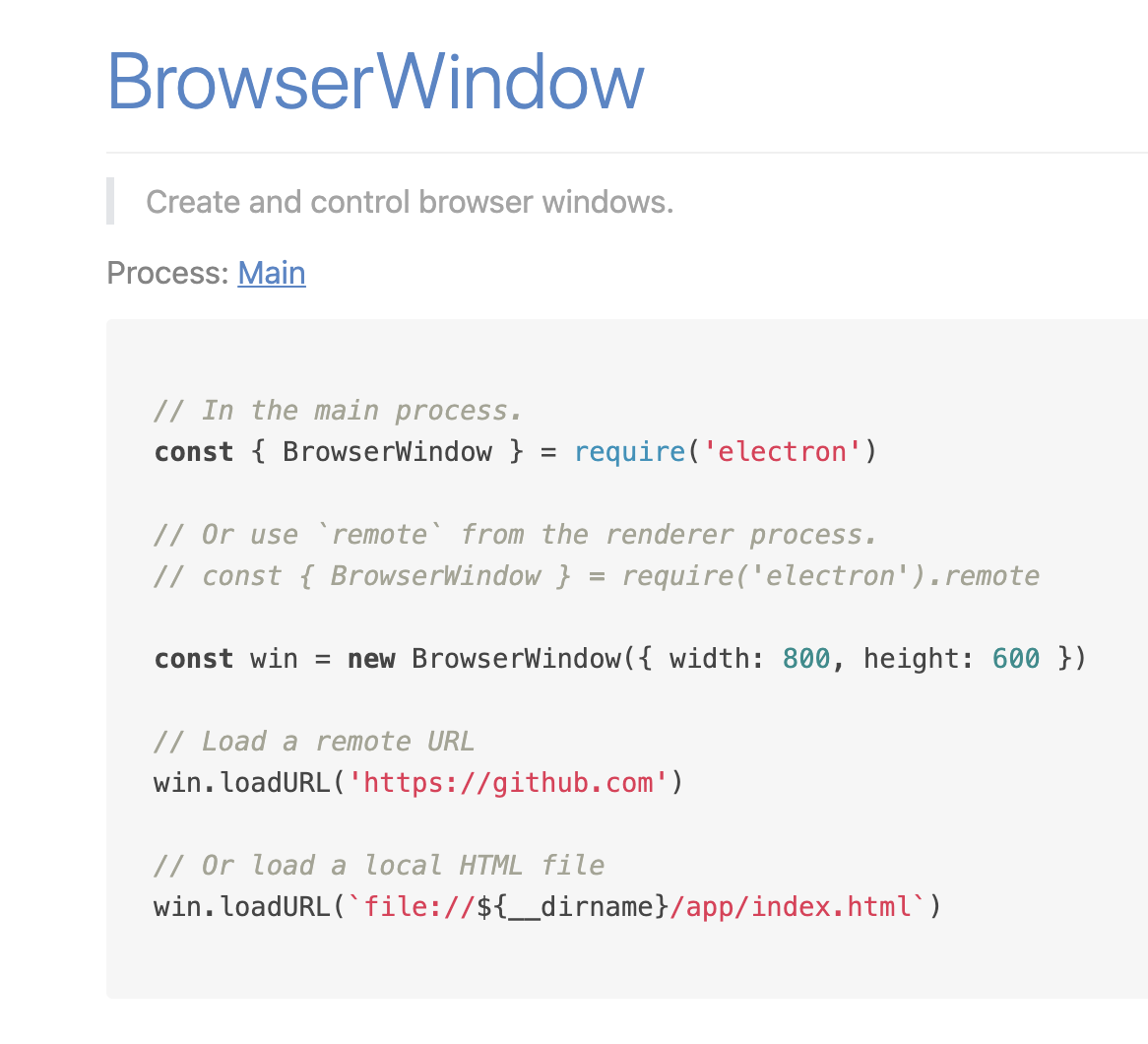
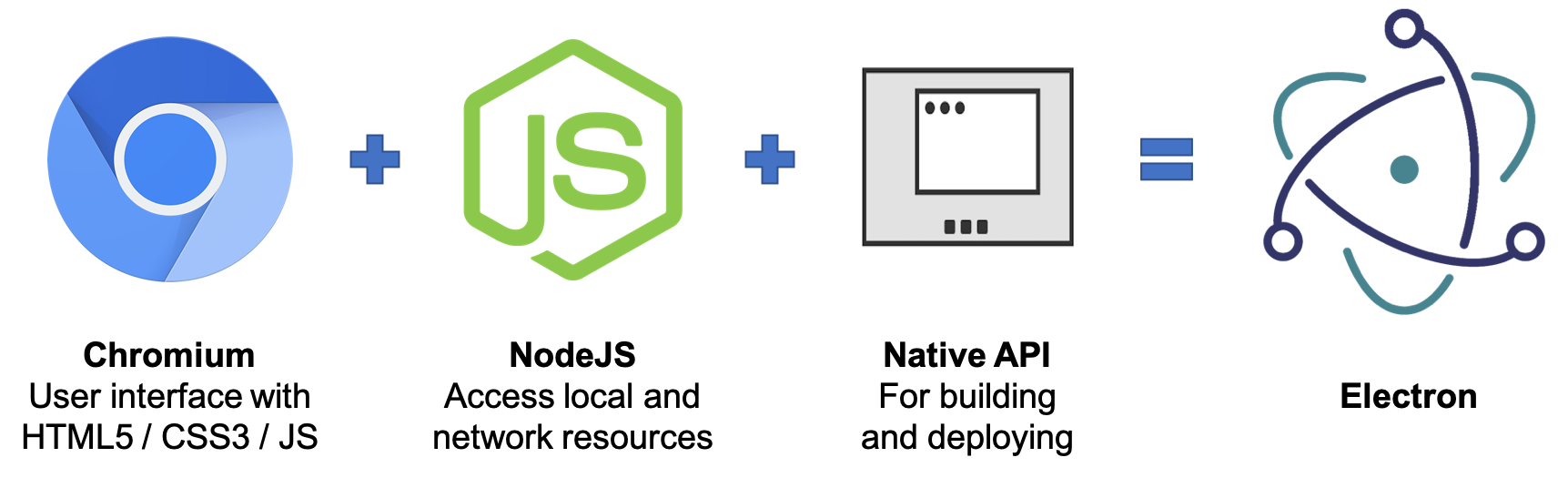
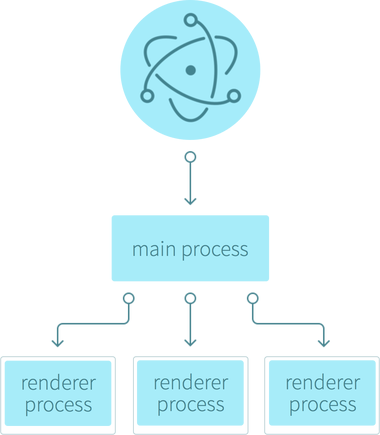
这个问题的答案很简单,Electron 就是 Chromium(Chrome 内核)、Node.js 和系统原生 API 的结合。它做的事情很简单,整个应用跑在一个 main process(主进程) 上,需要提供 GUI 界面时则创建一个 renderer process(渲染进程)去开启一个 Chromium 里的 BrowserWindow/BrowserView,实际就像是 Chrome 的一个窗口或者 Tab 页一样,而其中展示的既可以是本地网页也可以是线上网页,主进程和渲染进程间通过 IPC 进行通讯,主进程可以自由地调用 Electron 提供的系统 API 以及 Node.js 模块,可以控制其所辖渲染进程的生命周期。
Electron 做到了系统进程和展示界面的分离,类似于 Chrome或小程序的实现,这样的分层有利于多窗口应用的开发,天然地形成了 MVC架构。这里仅对其工作原理做大致介绍,并不会详尽阐述如何启动一个 Electron App 乃至创建 BrowserWindow 并与之通讯等,相反,本系列文章将着重于介绍适合 Web 开发者在编码之余需要关注的代码层次、测试、构建发布相关内容,以「腾讯文档桌面端」开发过程作为示例,阅读完本系列将使读者初步了解一个 Electron 从开发到上线所需经历的常见流程。
在这里,笔者将着重介绍与读者探讨以下几个 Electron 开发相关方面的激动人心的主题:
我只有一台 MacBook,可以用 Electron 开发出适用于其他平台的 App 吗?
我需要为不同平台分发不同的版本吗?它们的依赖关系如何?
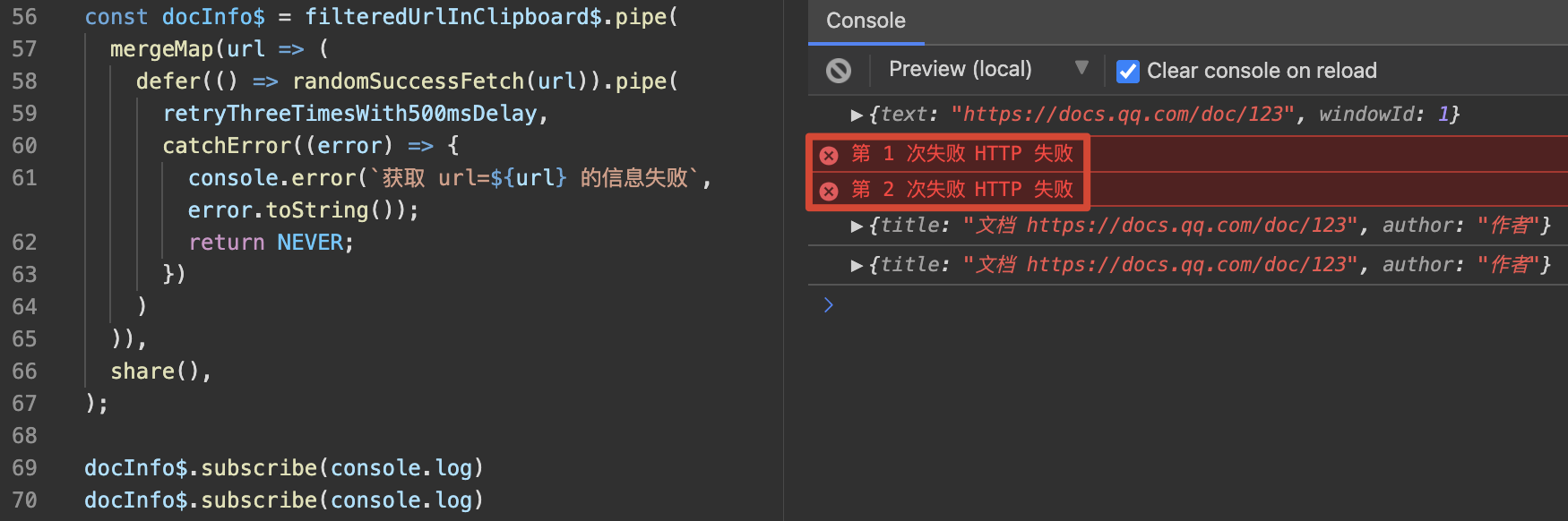
如何让用户觉得我开发的应用是可信任的和被稳定维护的?
我想让用户在”更多场景”下使用我的应用,我该怎么做?
我是一个 Web 开发者,Electron 看起来是 C/S 架构,应该如何设计消息传递机制?
用 Electron 开发的 App 可测试性如何,可以在同一套测试配置下运行吗?
不用担心,以上问题的回答都是”Yes,Electron 都能做到”。下面我们就进入第一个主题吧,如何构建你的 Electron 应用。
electron-builder 是具有同时打包出多个平台 App 的能力的,具体在 Mac 上是通过 Wine 这个兼容层来实现的,Wine 是 Wine Is Not an Emulator 的缩写,从名字里强调它不是一个模拟器,它是对 Windows API 的抽象。打包后的应用与 Windows 上构建的应用没有区别,但构建时的 process.platform 会被锁在 ‘darwin’ 即 macOS,这是个看起来微不足道,但实则遇到会让人抓耳挠腮的情形,后面会详细展开。
但 Windows 就没有这么好运气了,笔者并没有找到可以在 Windows 上打包出 macOS 可用执行文件的方式,所以上面的同时出两个平台可执行文件的方式亲测还是只能给 macOS 用的。
本文简述了通过 Electron 构建应用过程中采用不同方式和配置打包文件、使用 electron-builder 构建可执行文件,同时用其提供的功能实现自动升级与文件关联,完成了在单个平台(macOS)开发并构建出跨端应用的任务。笔者接触 Electron 开发时间较短,行文中多是开发中所见所闻所感,如有错误纰漏之处,还望读者不吝包涵指正。后续文章将介绍在跨端开发中处理兼容性时遇到的问题,以及如何优雅地在产品设计和功能间进行取舍。
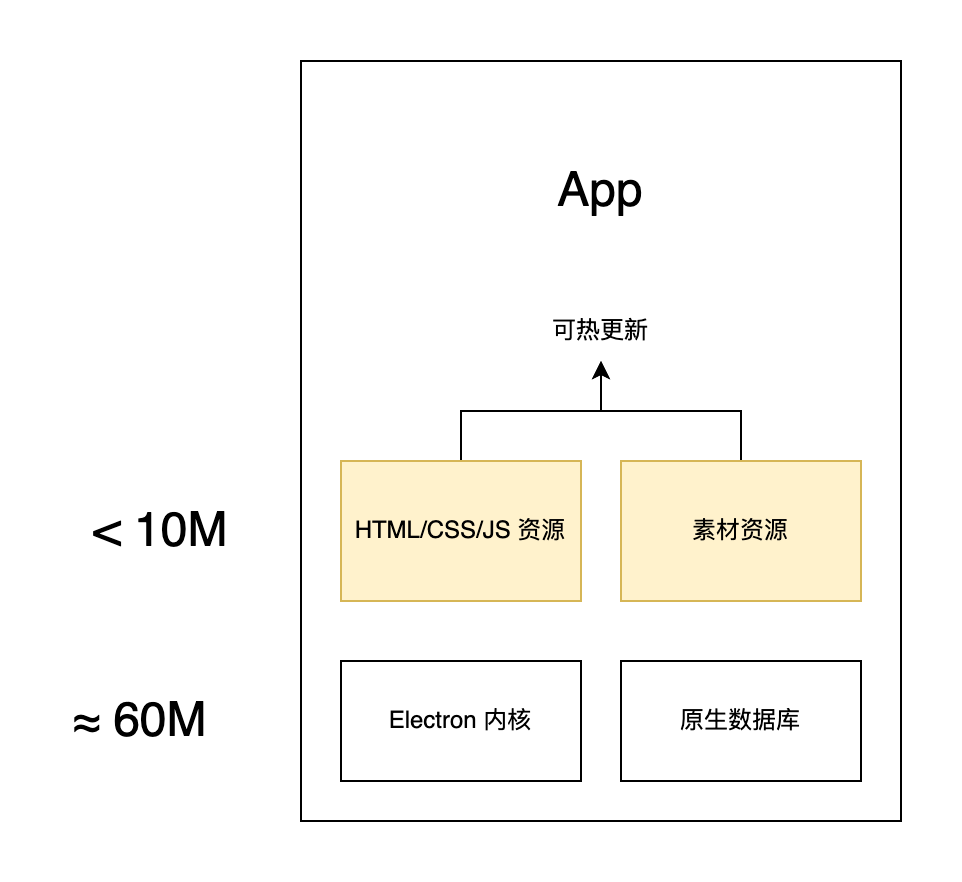
个人觉得 Electron 最精髓的应用不在于可以把网页打包成桌面应用,当然也是赋予了它很多桌面应用才有的功能,比如数据库以及和系统交互的能力。最重要的是引入了 B/S 架构以后,代码的打包阶段可以被分块分层,从而使开发和构建过程各取所需,一个预想的未来是可以基于 Electron 做下一代编辑器(Visual Studio Code++ …… 大误,逃)集成了从服务端到浏览器端的全链路。当然目前比较有用的是可以选择性地不打包一些库。