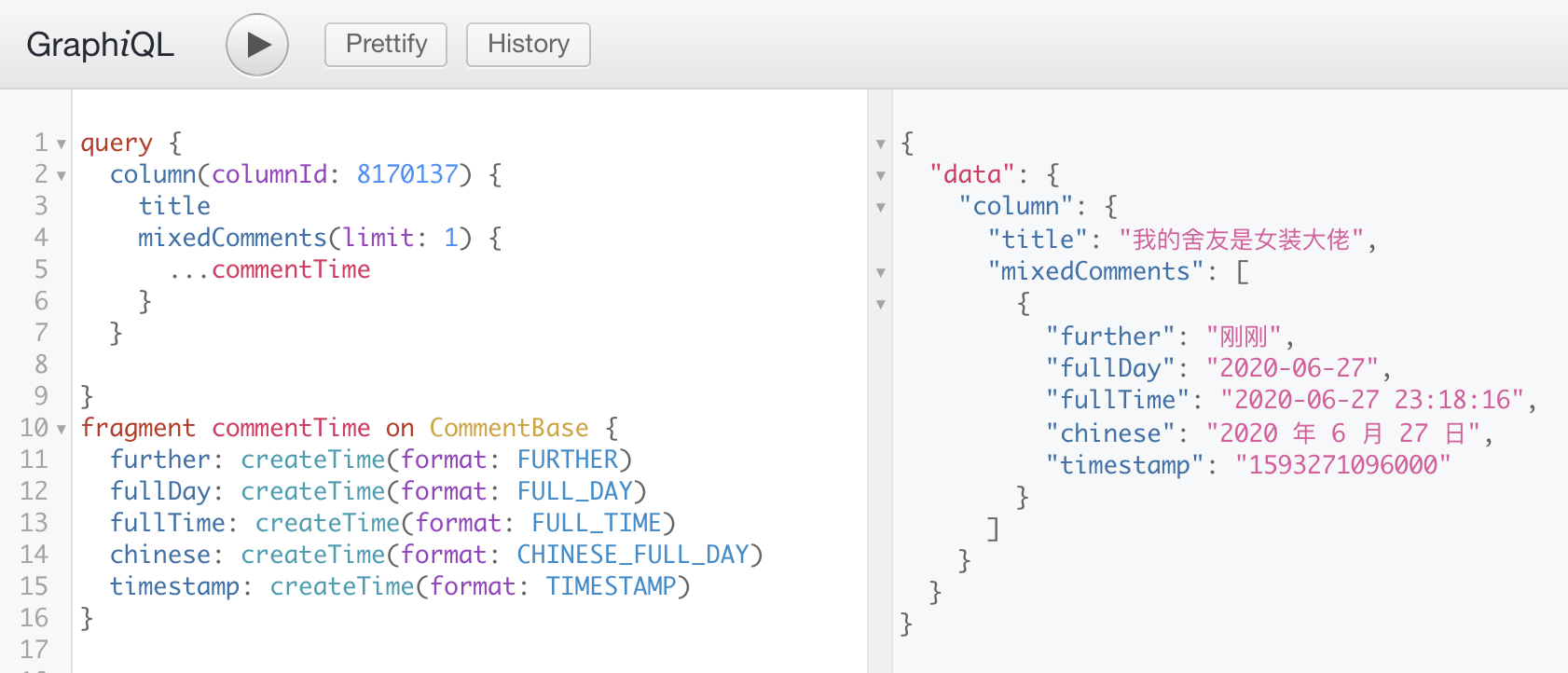
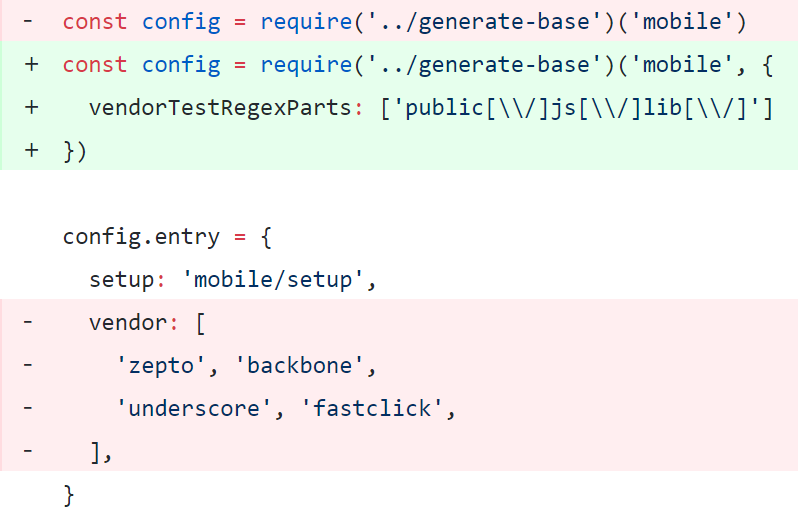
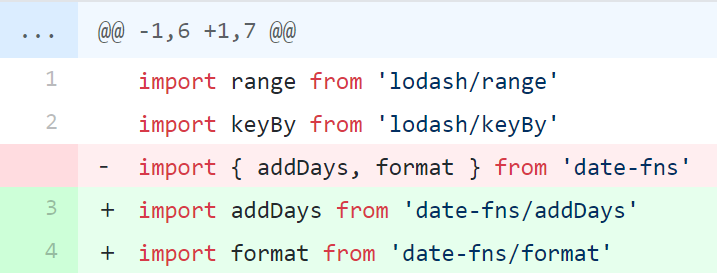
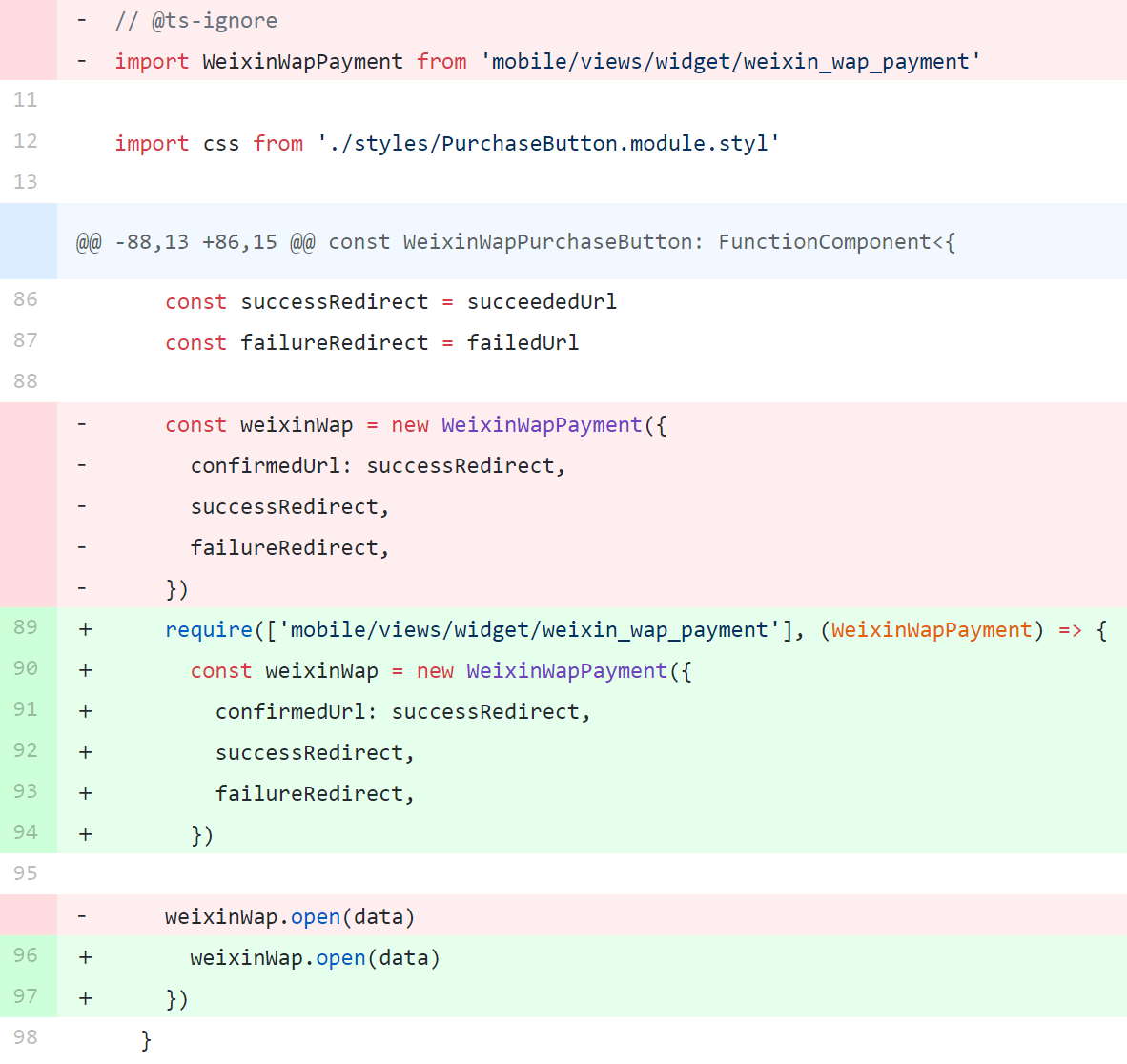
思路:最后需要得到一个二维数组,那基本都是 reduce 操作的话也应该是一个二维数组开头,每一次都把前一次结果得到的数组们尾部分别加上二维数组里的一项,也就是 m * n * [...prevResultList[i], list[j]],其中 m 和 n 分别是 prevResultList 和 list 的项数,这样也就成功实现了 m × n 的项数膨胀,至于降维操作我们有 flatMap 这个神器。面试时用了很丑陋的 reduce + map 嵌套,甚至还忘了把数组摊平……
if (error || stats.hasErrors()) { // errors should be serializable since it will go through processes errors = error ? error.toString() : stats.toJson().errors }
if (callback) { callback(errors) } if (errors) { reject(errors) } else { resolve() } }) })
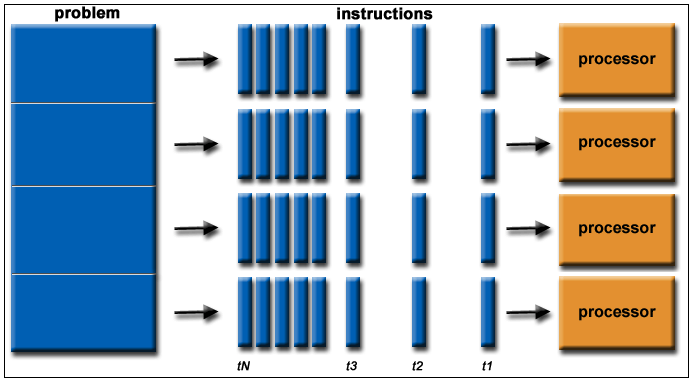
functionparallelRunner( module, taskCallback, parallel = true ) { const availableNumberOfCores = getAvailableNumberOfCores(parallel) let concurrency = 1// which means mergeMap will behave as concatMap let worker let total = 0 let completed = 0 let allScheduled = false
log('Parallel Running: ', module) log('Available Number of Cores: ', availableNumberOfCores)
const result$ = scheduled.pipe( mergeMap((data) => { // data is actually consumed here consumed.next(null) // worker[methodName] can only be invoked with serializable data // and returned value could be just plain RESULT or Promise<RESULT> returnfrom(taskCallback(worker || require(module), data)) }, concurrency), share() ) result$.subscribe({ complete: function() { if (worker) { worker.end() } }, next: function() { completed += 1 if (allScheduled && completed === total) { scheduled.complete() } }, error: function(err) { throw err } })
consumed$.subscribe(() => { // `afterComplete was defined` means there is no more data if (!afterComplete && afterConsume) { afterConsume() } })
result$.subscribe({ complete: () => { if (afterComplete) { afterComplete() } }, next: (data) => { stream.push(data) // if returned value is false means stream ends or meets highWaterMark // but we don't care since we use rxjs to control concurrency } })
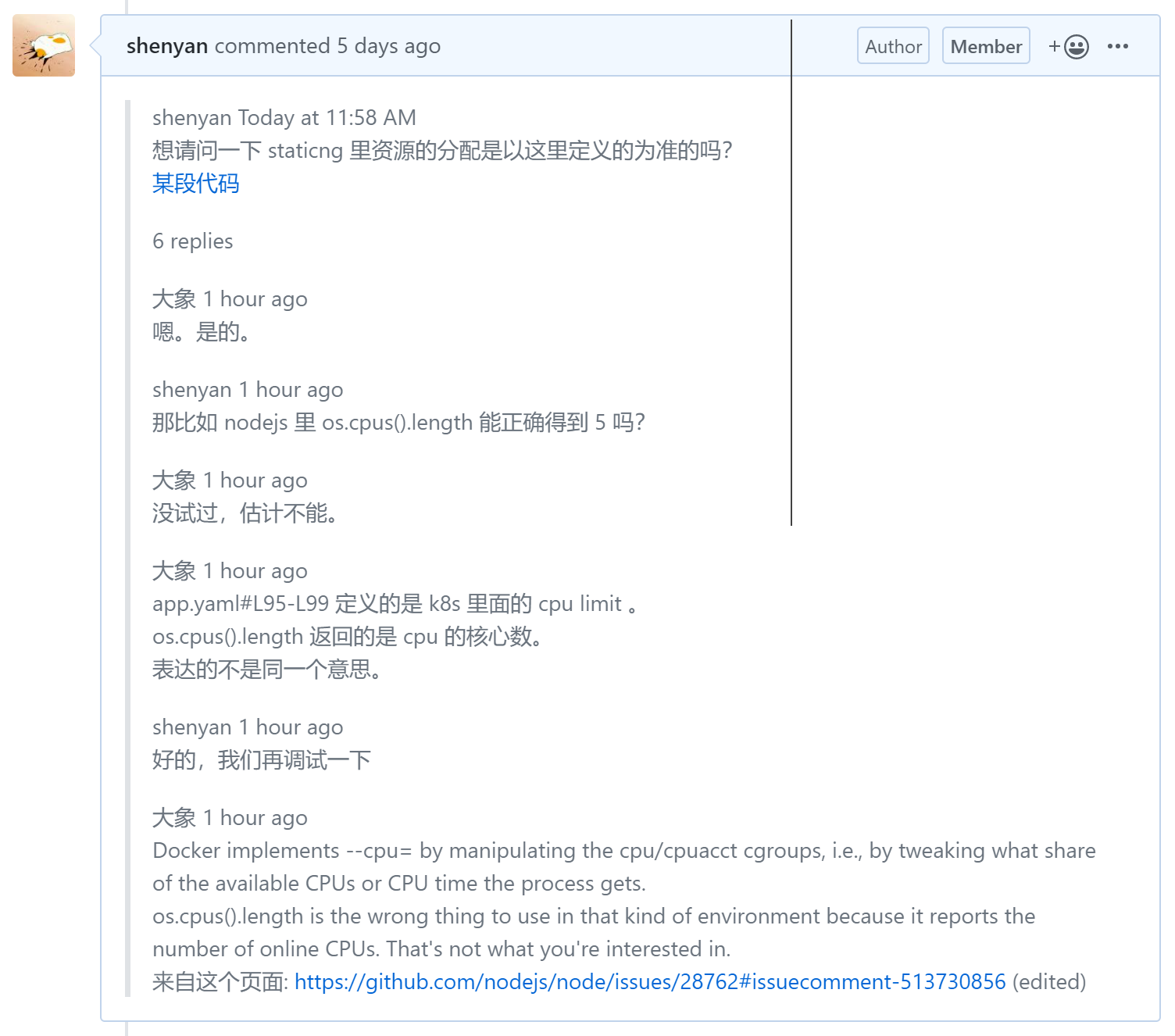
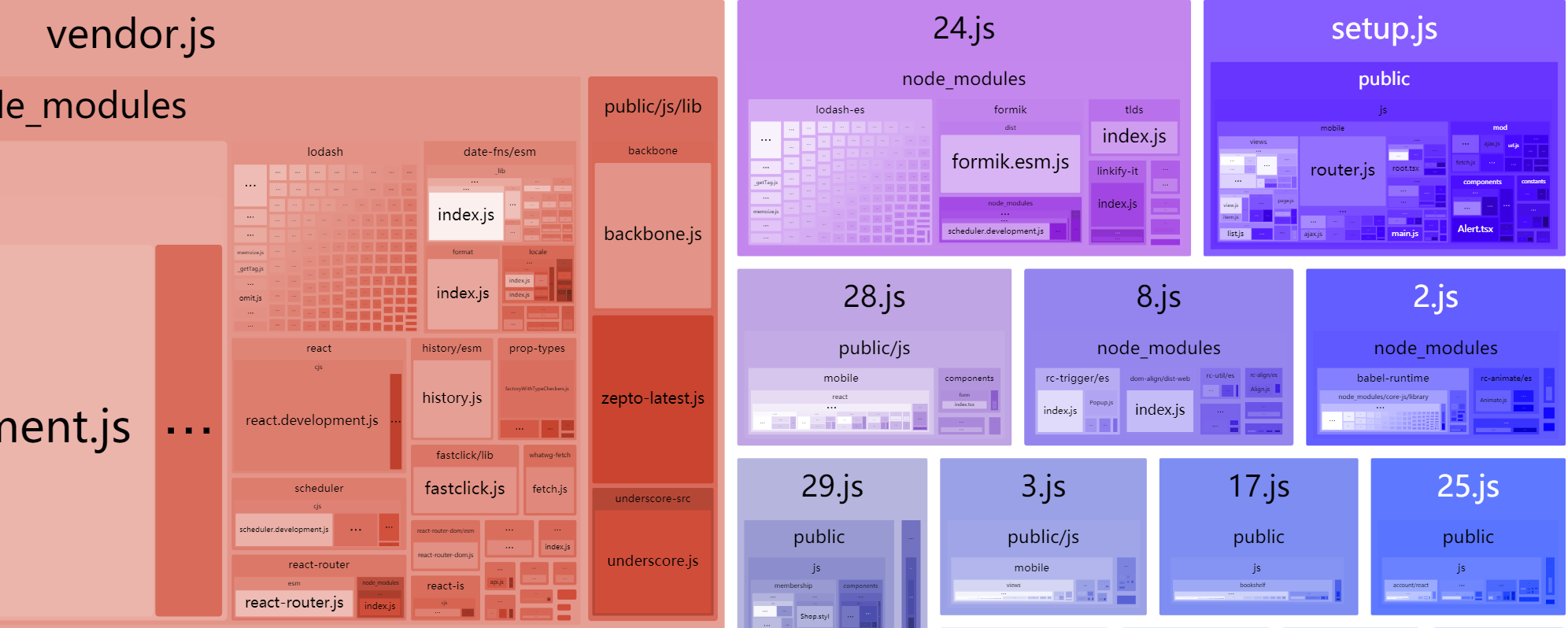
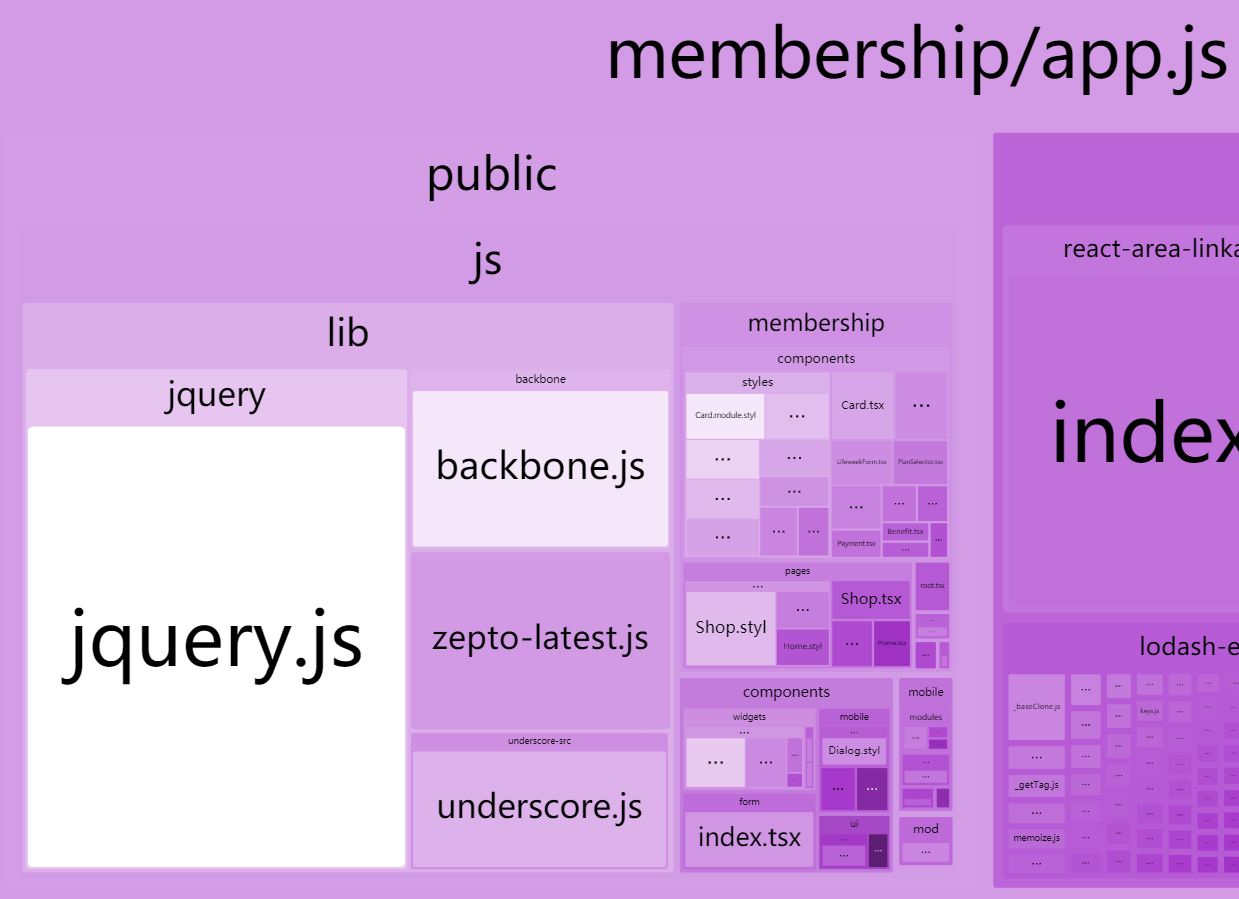
// Staticng has CPU limit of 5 on k8s, so we can't use os.cpus().length which // reports the number of online CPUs, but running with 4 threads is fast enough. // https://github.com/nodejs/node/issues/28762#issuecomment-513730856 constPRODUCTION_PARALLEL_NUMBER = 4
2020 年目前在做的最复杂的项目是将基于 Draft.js 深度定制开发的 web 编辑器适配到移动端,因为数据上牵涉到很多转换过程 native 端要从头开发的话成本过高,并且发现 web 并不能很正常地识别虚拟键盘弹出与否,于是将下图所示的工具栏通过 native 端单独进行开发与 web 集成,以获得更好的使用体验。
‘unordered-list-item’ in syncState.disabled_buttons
AEW.toggleBlockType(‘unordered-list-item’)
引用
‘blockquote’
‘blockquote’ in syncState.disabled_buttons
AEW.toggleBlockType(‘blockquote’)
图片
‘FIGURE’
‘atomic’ in syncState.disabled_buttons
AEW.selectImage()
代码块
‘code-block’
‘code-block’ in syncState.disabled_buttons
AEW.insertCodeBlock()
分割线
‘PAGEBREAK’
‘ atomic’ in syncState.disabled_buttons
AEW.insertPagebreak()
分行
‘ atomic’ in syncState.disabled_buttons
AEW.insertSoftNewLine()
撤销
syncState.undo_disabled
AEW.undo()
重做
syncState.redo_disabled
AEW.redo()
清除行内样式
AEW.removeFormat()
优先级原则:
先判断是不是 disabled
toggle > native 帮我 > 交给你了 web > insert/update/remove
上面就是编辑器跨端通讯的基本形式了,简单来说 web 端每次 React componentDidUpdate 会把状态同步给 native 端,保证工具栏的及时性。当用户点击工具栏中可用按钮时,首先判断是不是需要和 web 进行状态判断,毕竟前一步只是判断能不能触发,触发以后的行为需要结合更具体的数据状态。然后是如果发现需要更多用户输入(比如弹窗输入框或勾选项等等)就需要唤起 native 的方法(native 帮帮我),如果没有这一步就可能是 web 专享操作,无关更多状态,比如上传图片或者撤销重做等等,这种情况就全权交给 web 了。最后则是 native 端二次调用 web 的方法,通常是关掉弹窗以后传递数据去改变 web 的状态。