再谈业务逻辑
我面试过一些岗位,也面试过很多人,基础的岗位问的最多的大概就是对框架的理解,对语言基础的掌握等等,但如果是高级岗位往往问到对市场大环境的感悟和对业务逻辑的理解,体现了工具的应用必然是为完成目的服务的标准。
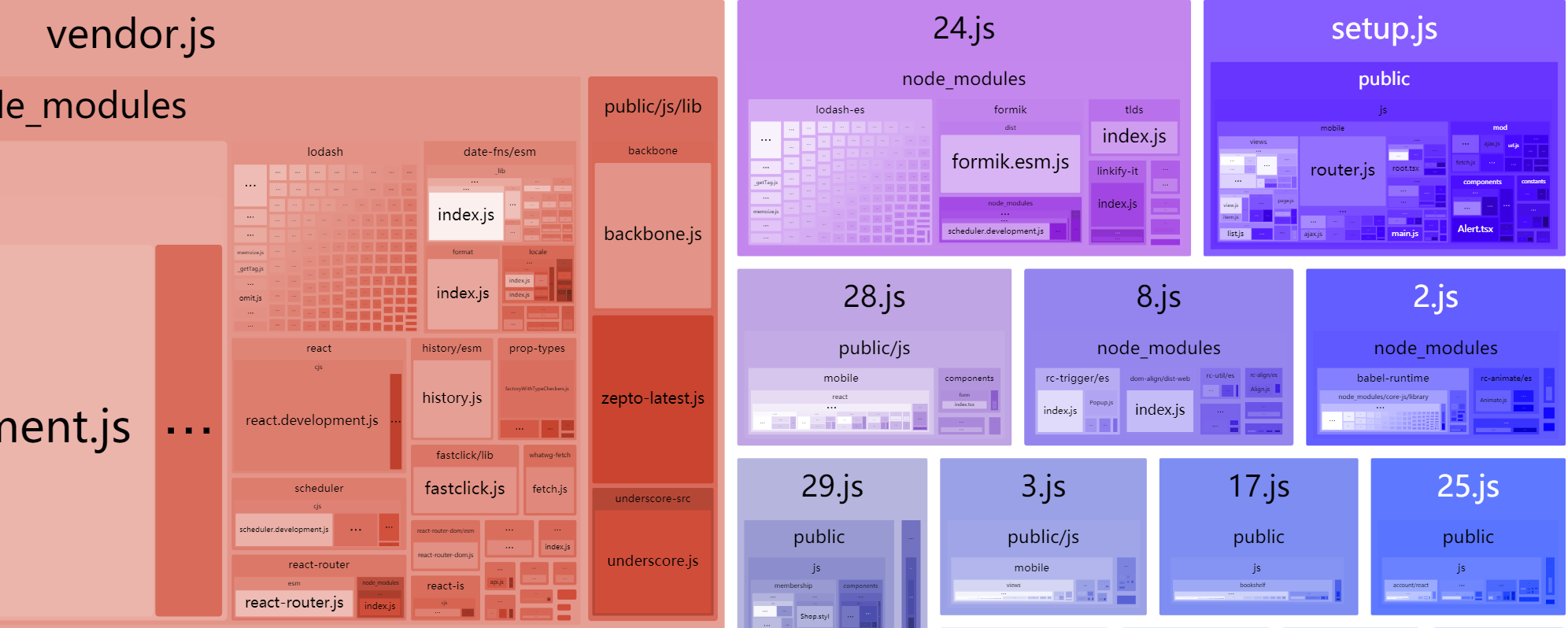
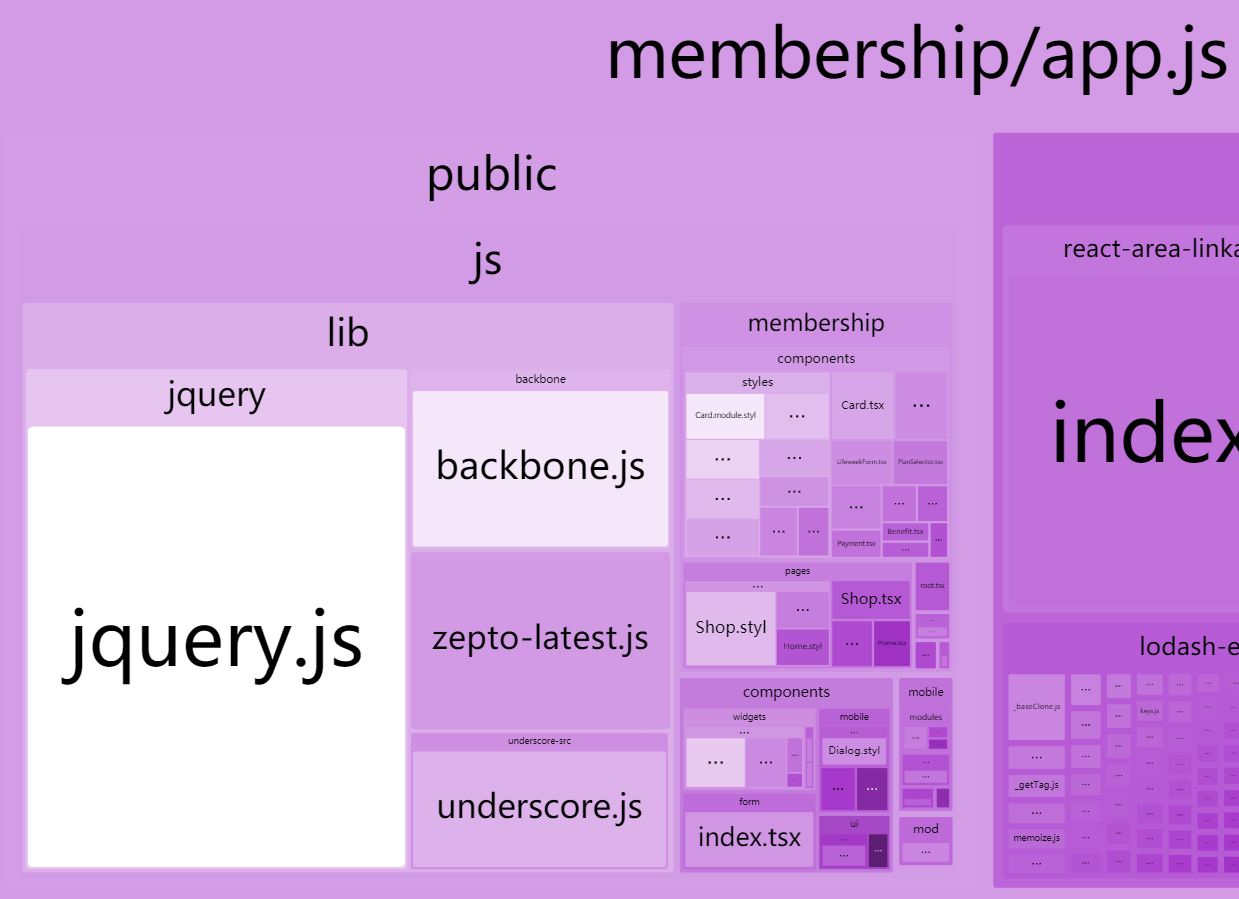
实际开发中,由于前后端现在工种的分离,业务逻辑的归属是很大的问题。
后端面向数据库和第三方服务集成,数据库总是以最小业务模型为基准,考虑扩展性进行建模,而第三方服务与领域模型融合则需要对业务逻辑进行抽象化,比如支付接口需要考虑本身提供的商品种类和第三方支付的种类进行分别编码并抽取公共逻辑,常见的形式有 Adapter(适配器模式)等。
前端当下也很复杂,虽然有了一些基础组件,但随着业务的深入,组件上难免多出很多随着各种特殊使用场景分别配置的参数,甚至一个组件接受几十个参数来配置,可能也有同学一看这不行啊,感觉封装了几个配置好的组件供业务使用,但上面的过程多了以后,组件变得又深又长,深体现在封装层级上,长体现在单个组件的长度上,比如封装一个电子书的展示列表。
图片 -> 封面 -> 带标签的封面 -> 电子书 -> 书籍列表 -> 可无限加载的书籍列表
这时如果要把「图片的尺寸」或者「可点击与否」传递给最内部的组件,就需要一层层从上面传下来,React 有 context 方法来在组件间传递参数,但这毕竟是不可见的,需要自己去 useContext 来得到。ES6 中提供了 Reflect 对象,比如 Reflect.getMetadata('design:paramtypes', target) 可以得到在参数里定义的参数类型,Angular 的控制反转和依赖注入就是依靠这实现的。这为我们提供了一些可以想象的思路,当然本质上它只能解决编码上的便利性,组件的层级和复杂度并没有因此降下来。
当前前后端通讯主要靠两种方式
- 首屏页面内 script 注入初始数据
- AJAX 接口
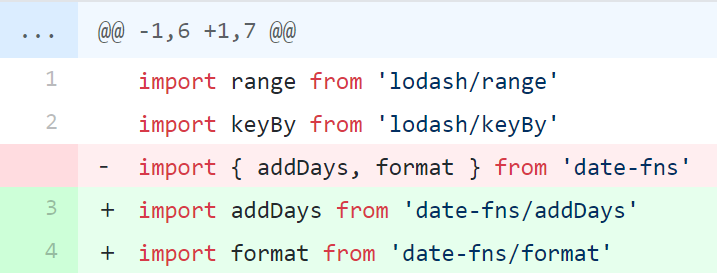
阅读站新的接口优先考虑 GraphQL,GraphQL 是一种面向领域模型的非常好的查询语言,我们不再需要多次往返前后端通讯获得更多数据,或者是重复定义各种 build_xxx_entity,只需要一次定义,任何用到单个字段的地方都只用写字段名就可以使用,可以说极大地降低了边际成本,而且越用收益越高。当然有同学会问那如果大批量查询的问题呢?Facebook 给出了 DataLoader 的方案,但我们的 peewee 版本以及早期的 hack 写法限制了我们真正将 ORM <==> GraphQL 的过程,现在其实是手动 ORM <==> 字段,带缓存的字段 <==> GraphQL。
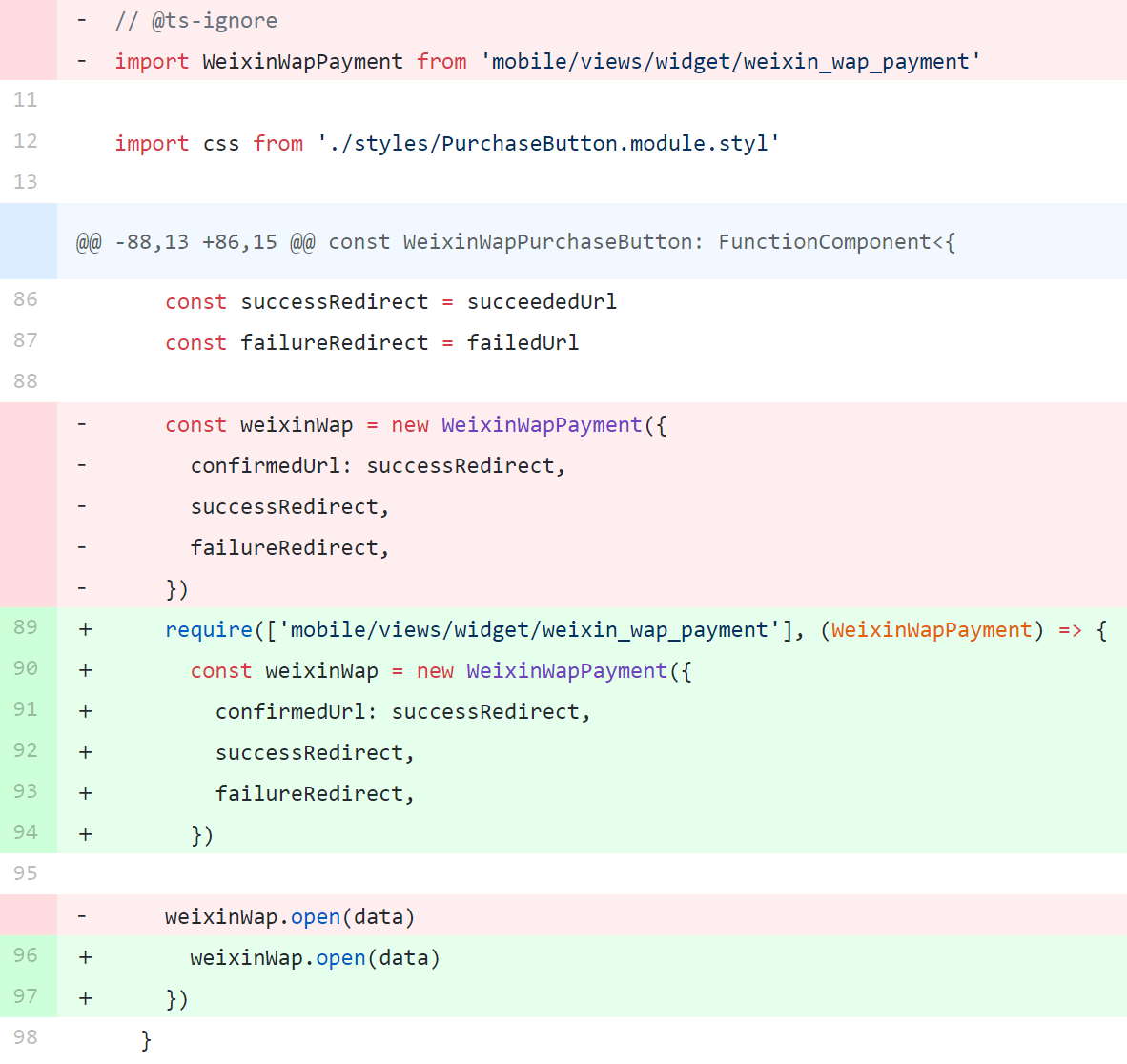
当后端和接口都做到了尽量少耦合业务逻辑时,业务逻辑就大量堆积在表单 POST 接口和前端展示逻辑上,又因为表单校验因 js 和 python 没法互通,需要前后端分别实现,而展示逻辑则是大多硬编码在组件内。这点其实很吓人。表单方面有 JSON Schema 的方案,但因为 Python 这种胶水语言快读开发的节奏每每难以落地,只是可惜展示上没法脱离业务组件进行编码,之前有过在 App 上设计根据 type 来组合 widget 的展示形式,但一旦需求变动代码就变得非常臃肿。
一种现有的整理业务逻辑的形式是把 Business Logic 存到数据库中 …… 简单来说,如果数据库可以方便地表达因果关系,或许这是一种可行的方案。还有就是很通用的配置文件方式,也是我们搭建开发环境的方式,通过脚本配置在环境初始化时载入一系列的变量最终构建出符合业务需要的开发环境。
理想的情形可能是,前端只提供组件库和组件间的组合逻辑,后端只提供数据的存储和加工工具,业务逻辑由第三方提供配置,设置极限值和用户可选值,用户可以在享有最多自主权的情形下使用 web 产品,当然这也只是一种美好的愿望……毕竟当下都是想把产品做到尽善尽美,只给用户一种最好的选择,可这是不是用户想要的呢?做得越多也许越错呢?没有人真的会去想,大家都是假装想想罢了。