思路:最后需要得到一个二维数组,那基本都是 reduce 操作的话也应该是一个二维数组开头,每一次都把前一次结果得到的数组们尾部分别加上二维数组里的一项,也就是 m * n * [...prevResultList[i], list[j]],其中 m 和 n 分别是 prevResultList 和 list 的项数,这样也就成功实现了 m × n 的项数膨胀,至于降维操作我们有 flatMap 这个神器。面试时用了很丑陋的 reduce + map 嵌套,甚至还忘了把数组摊平……
if (error || stats.hasErrors()) { // errors should be serializable since it will go through processes errors = error ? error.toString() : stats.toJson().errors }
if (callback) { callback(errors) } if (errors) { reject(errors) } else { resolve() } }) })
functionparallelRunner( module, taskCallback, parallel = true ) { const availableNumberOfCores = getAvailableNumberOfCores(parallel) let concurrency = 1// which means mergeMap will behave as concatMap let worker let total = 0 let completed = 0 let allScheduled = false
log('Parallel Running: ', module) log('Available Number of Cores: ', availableNumberOfCores)
const result$ = scheduled.pipe( mergeMap((data) => { // data is actually consumed here consumed.next(null) // worker[methodName] can only be invoked with serializable data // and returned value could be just plain RESULT or Promise<RESULT> returnfrom(taskCallback(worker || require(module), data)) }, concurrency), share() ) result$.subscribe({ complete: function() { if (worker) { worker.end() } }, next: function() { completed += 1 if (allScheduled && completed === total) { scheduled.complete() } }, error: function(err) { throw err } })
consumed$.subscribe(() => { // `afterComplete was defined` means there is no more data if (!afterComplete && afterConsume) { afterConsume() } })
result$.subscribe({ complete: () => { if (afterComplete) { afterComplete() } }, next: (data) => { stream.push(data) // if returned value is false means stream ends or meets highWaterMark // but we don't care since we use rxjs to control concurrency } })
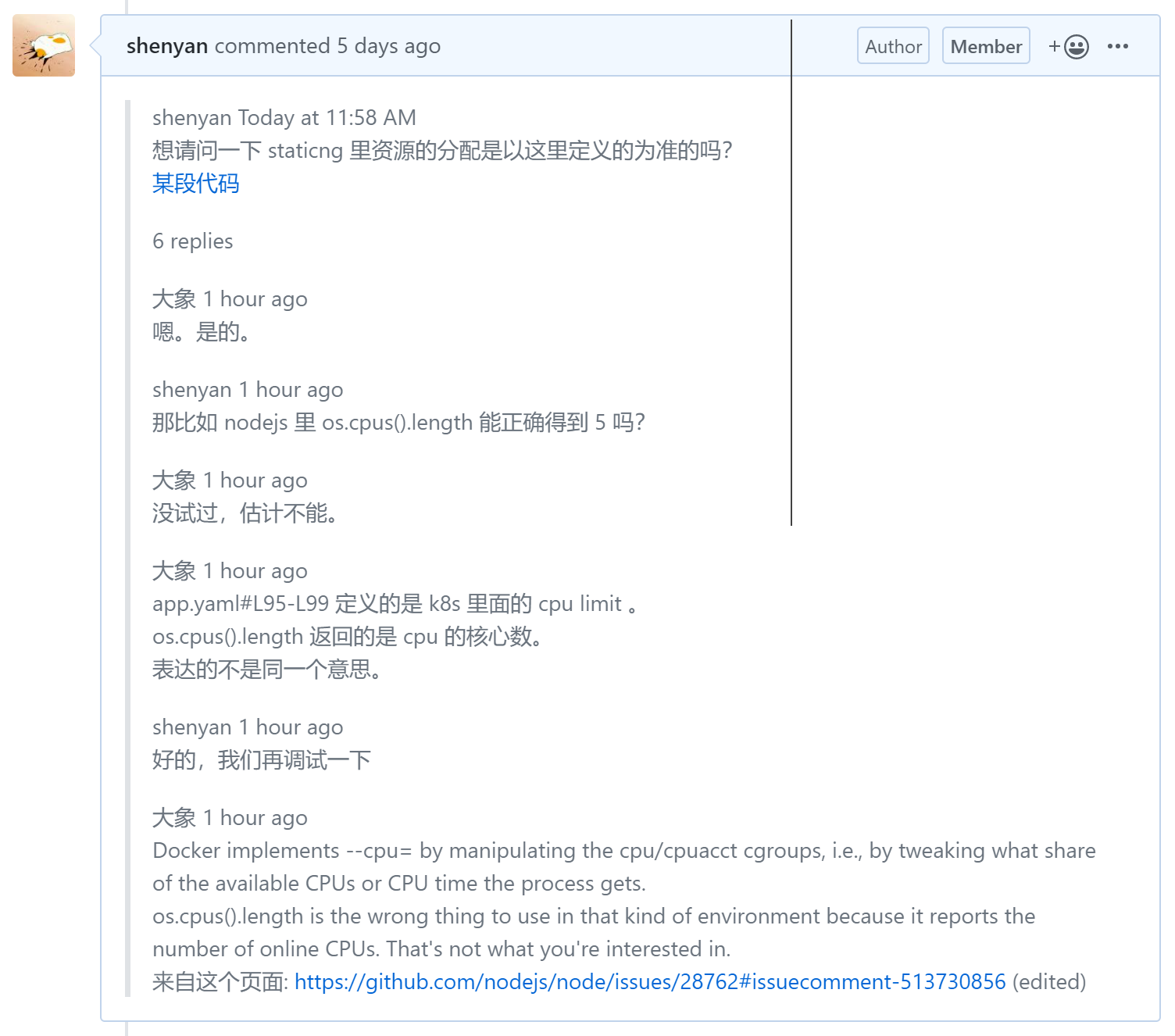
// Staticng has CPU limit of 5 on k8s, so we can't use os.cpus().length which // reports the number of online CPUs, but running with 4 threads is fast enough. // https://github.com/nodejs/node/issues/28762#issuecomment-513730856 constPRODUCTION_PARALLEL_NUMBER = 4