复盘一次 gulp & webpack 构建优化
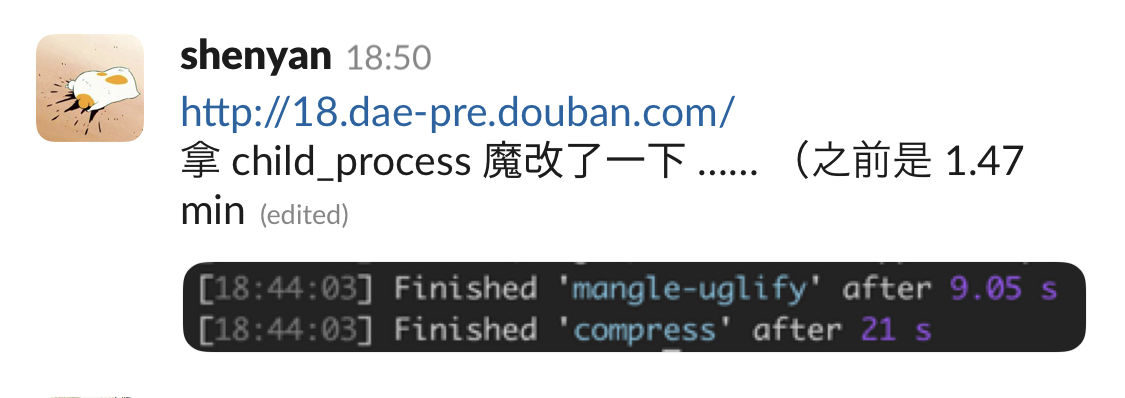
接续前一篇《并行化密集型计算》,发现实际上线时 parallel terser 并没有提升速度。反而比单线程还要慢,这就有点不科学了。首先想本地跑起来没有出错,大概不是程序逻辑问题,再想想看,估计是配置问题,与 SA 进行了一波有力的交流。
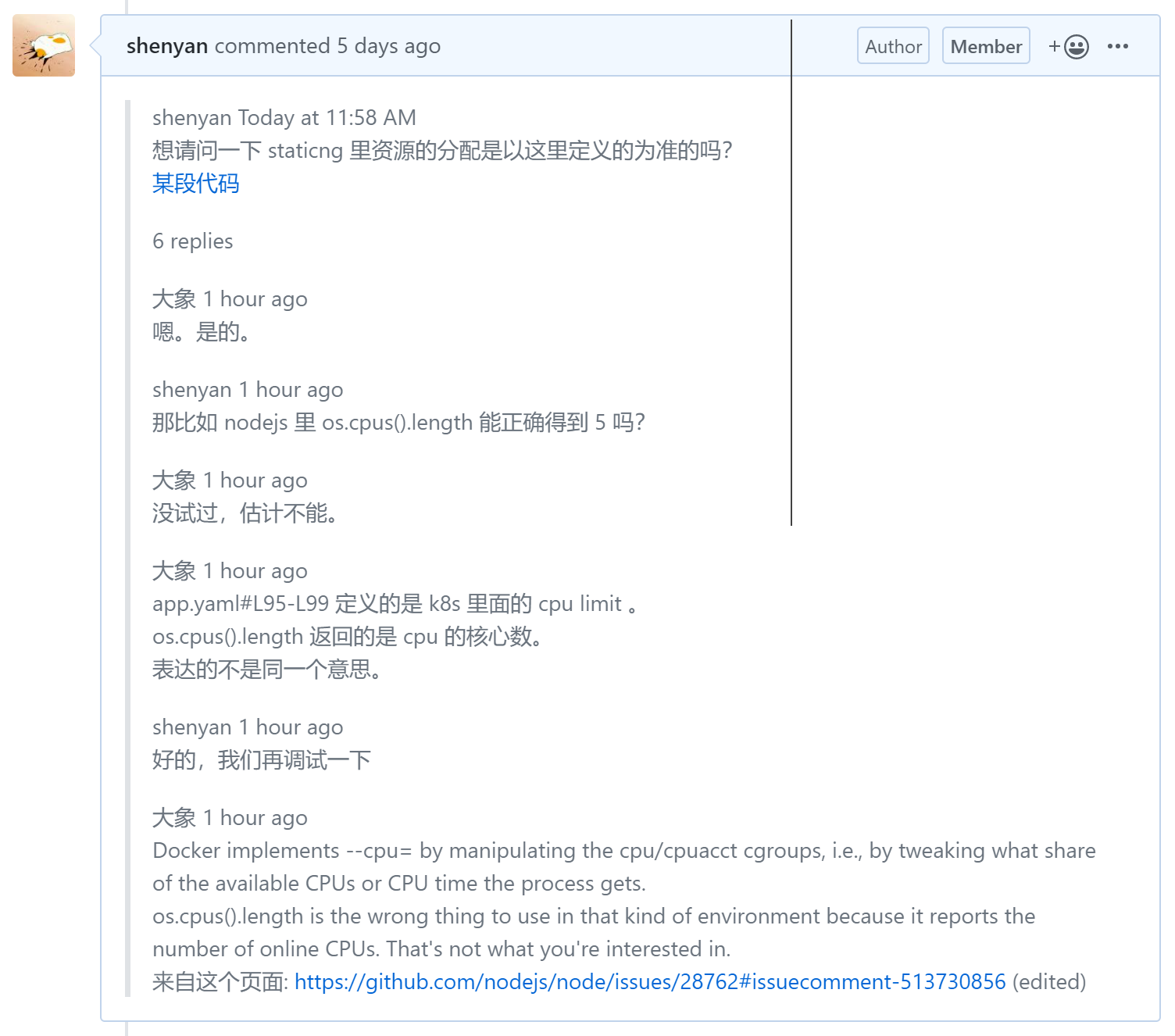
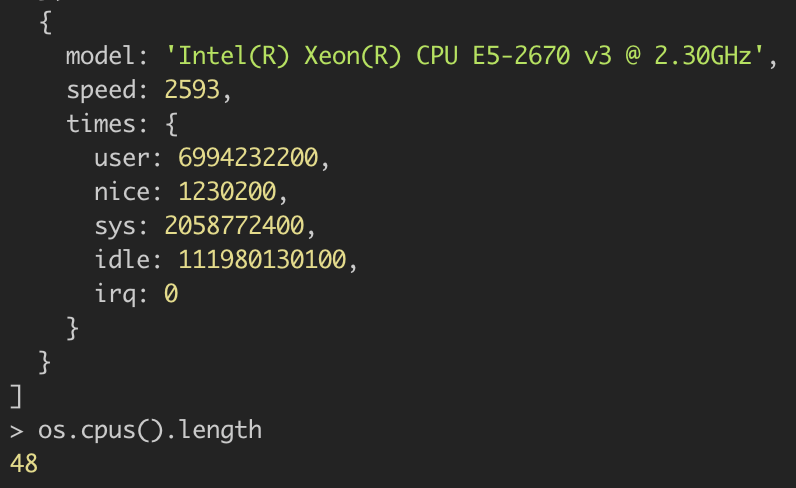
原来 os.cpus() 拿到的是真实的计算机 CPU 核数,而 k8s 会限制容器的 CPU 使用量,所以我们应该手动将 NODE_ENV=production 时的并发数限制在 5 以内。
进一步思考这种 utility 和 business 代码混写在一起的方式极其耦合,想要更高效地发挥代码的作用必须分离它们,于是就借鉴了 terser-webpack-plugin 中对于 jest-worker 的应用改了一下,并将其应用于 webpack 的打包,取得了不错的效果。
1 | gulp.task('webpack', function() { |
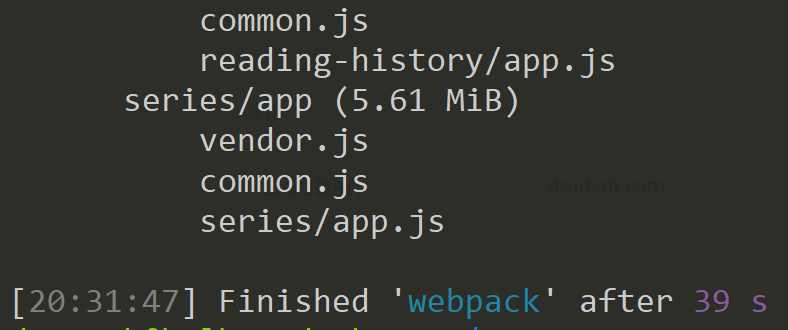
但实际到了线上 webpack 依然花了将近 4 分钟,与此同时 gulp parallel terser 已经稳定在 1 分钟之内了。这时一段异常的日志引起了我的注意。

原来 webpack 里自带的 terser-webpack-plugin 会在 production mode 下自动开启,又是 48 线程 …… 4 * 48 = 192 线程,OMG,不跑崩让 SA 来请喝茶才怪了。但转念一想,好像后面我们还会对各种文件都 terser 一遍,在 webpack 里压缩似乎是没有必要的?于是乎直接禁用 optimization.minimize 就可以了。
期间又优化了一下 parallel-runner,处理了一下 stream/rxjs observable/worker 之间的 back pressure 问题。简单说就是当 rxjs mergeMap 把一个值传到 worker 里去处理时才算作 consumed,会继续向上游 pull 下一个数据,这样就把上下游的数据链接给建立起来了,而不是之前那样全部 pull 下来堆在 mergeMap 外面,容易形成 memory leak。
Call the callback function only when the current file (stream/buffer) is completely consumed.
parallel-runner 把 data(vinyl File) 放到 worker 去处理标志该数据为 consumed(实际结果会在 result$ 里被 push 给下游的 writable stream),然后 stream 会根据是否 end 或者到达 highWaterMark 自动去 read(pull) 上游 readable stream 的下一个数据,也就是执行我们传入的 transform 方法。数据可能堆积在 mergeMap 外最多一个,因为那个数据不进入 mergeMap 就不会继续触发 consumed,之前是一口气全 read。
最后,规范化了一下 webpack 出错时向 main process 通报错误的方法,该出错就出错,不要静默失败到上线时出大问题。
1 | return new Promise((resolve, reject) => { |
至此,这次优化 gulp & webpack 打包构建流程的优化工作就算告一段落了,实际上大概处理了以下几个问题:
- 将重复性的任务放到多线程并行执行
- 提取公共代码转成 utilities
- 区分本地开发与生产环境,尊重基础设施对于计算资源的分配规则
- 剔除多余的步骤避免重复计算(侧面说明不要替用户预先做决定的重要性)
- 向官方推荐实现靠拢,以求符合标准融入开源库的生态环境
下面直接贴出了 parallel-runner 的代码,小弟手艺不佳,写得不好,各位如有需要可以在此基础上稍加改动以适应业务需要。
1 | // Inspired by terser-webpack-plugin. |
实际应用于 terser 的代码
1 | function parallelTerser(needMangle) { |